# I. LOAD LIBRARIES
# -----------------------------------------------------------------------------
suppressPackageStartupMessages({
library(tidyverse)
library(data.table)
library(patchwork)
library(igraph) # For network analysis
library(ggraph) # For network visualization
library(gganimate) # For animations
library(viridis) # For color palettes
library(scales) # For scaling functions
})
# For reproducibility
set.seed(42)
# II. CORE PARAMETERS AND CONFIGURATION
# -----------------------------------------------------------------------------
DEFAULT_PARAMS <- list(
N_ORGS = 200, # Number of organizations (agents)
N_SKILLS = 30, # Number of skills
N_ITERATIONS = 100, # Number of time steps in the simulation
BASE_UNCERTAINTY = 0.15, # Probability an org feels uncertain about a missing skill
BASE_IMITATION = 0.6, # Probability an org will attempt to imitate for an uncertain skill
ASP_INTERCEPT = 0.5, # Base probability for aspirational imitation
ASP_SLOPE = 0.8, # Effect of status gap on aspirational imitation
PROX_INTERCEPT = 0.6, # Base probability for proximity imitation
PROX_SLOPE = 1.0, # Effect of status gap on proximity imitation
MAX_TARGETS = 5 # Maximum number of referents to consider
)
# III. CORE MODEL FUNCTIONS (AGENTS & MECHANISMS)
# -----------------------------------------------------------------------------
#' Initialize the set of skills with varying transferability
initialize_skills <- function(params) {
data.frame(
skill_id = 1:params$N_SKILLS,
transferability = rbeta(params$N_SKILLS, shape1 = 2, shape2 = 2)
)
}
#' Create the population of organizations and their initial skill portfolios
create_organizations <- function(skills_df, params) {
orgs_df <- data.frame(
org_id = 1:params$N_ORGS,
status = rbeta(params$N_ORGS, 2, 5)
)
orgs_df$status <- pmax(0.05, pmin(0.95, orgs_df$status))
# Create initial skill portfolios
portfolio_list <- list()
for (org_idx in 1:params$N_ORGS) {
org_id_current <- orgs_df$org_id[org_idx]
org_status_current <- orgs_df$status[org_idx]
n_skills_for_org <- min(rpois(1, 6) + 2, params$N_SKILLS)
skill_probs <- skills_df$transferability * org_status_current +
(1 - skills_df$transferability) * (1 - org_status_current)
selected_skills <- sample(skills_df$skill_id, size = n_skills_for_org,
prob = skill_probs, replace = FALSE)
if (length(selected_skills) > 0) {
portfolio_list[[org_idx]] <- data.frame(
org_id = org_id_current,
skill_id = selected_skills,
iteration_acquired = 0
)
}
}
portfolio_df <- do.call(rbind, portfolio_list)
return(list(organizations = orgs_df, portfolio = portfolio_df))
}
#' Calculate the probability of imitation based on the core theoretical model
calculate_imitation_prob <- function(focal_status, target_status, skill_transferability,
params, model_type = "theoretical") {
status_gap <- target_status - focal_status
if (model_type == "null") return(runif(1, 0.3, 0.5))
aspirational_weight <- if (model_type == "reversed") 1 - skill_transferability else skill_transferability
proximity_weight <- 1 - aspirational_weight
prob_aspirational <- params$ASP_INTERCEPT + params$ASP_SLOPE * status_gap
prob_proximity <- params$PROX_INTERCEPT - params$PROX_SLOPE * abs(status_gap)
final_prob <- (aspirational_weight * prob_aspirational) + (proximity_weight * prob_proximity)
return(pmax(0.05, pmin(0.95, final_prob)))
}
#' Find potential target organizations that have a specific skill
find_targets <- function(focal_org_id, skill_id, orgs_df, portfolio_df, params) {
orgs_with_skill_mask <- portfolio_df$skill_id == skill_id & portfolio_df$org_id != focal_org_id
orgs_with_skill <- unique(portfolio_df$org_id[orgs_with_skill_mask])
if (length(orgs_with_skill) == 0) return(data.frame())
targets <- orgs_df[orgs_df$org_id %in% orgs_with_skill, ]
n_targets <- min(params$MAX_TARGETS, nrow(targets))
if (n_targets > 0 && n_targets < nrow(targets)) {
targets <- targets[sample(nrow(targets), n_targets), ]
}
return(targets)
}
# IV. ANALYSIS FUNCTIONS
# -----------------------------------------------------------------------------
#' Calculate Gini coefficient for inequality measurement
calculate_gini <- function(x) {
n <- length(x)
x <- sort(x)
gini <- (2 * sum((1:n) * x)) / (n * sum(x)) - (n + 1) / n
return(gini)
}
#' Calculate dissimilarity index for skill segregation
calculate_dissimilarity_index <- function(events_data) {
if (nrow(events_data) == 0) return(0)
# Use target_status if available, otherwise use source_status as proxy
status_col <- if ("target_status" %in% names(events_data)) "target_status" else "source_status"
if (!status_col %in% names(events_data)) {
return(0) # Cannot calculate without status information
}
high_tau <- events_data$transferability > median(events_data$transferability)
high_status <- events_data[[status_col]] > median(events_data[[status_col]])
total_high_tau <- sum(high_tau)
total_low_tau <- sum(!high_tau)
if (total_high_tau == 0 || total_low_tau == 0) return(0)
high_tau_in_high_status <- sum(high_tau & high_status)
low_tau_in_high_status <- sum(!high_tau & high_status)
dissimilarity <- 0.5 * abs(high_tau_in_high_status/total_high_tau -
low_tau_in_high_status/total_low_tau)
return(dissimilarity)
}
#' Analyze emergent patterns from simulation results
analyze_emergent_patterns <- function(events_data, orgs_df) {
if (nrow(events_data) == 0) {
return(list(
segregation = 0,
speed = data.frame(),
concentration = data.frame()
))
}
# Add target status information if target_status column doesn't exist
if (!"target_status" %in% names(events_data)) {
events_data <- events_data %>%
left_join(orgs_df %>% select(org_id, target_status = status),
by = c("target_org_id" = "org_id"))
}
# Segregation index
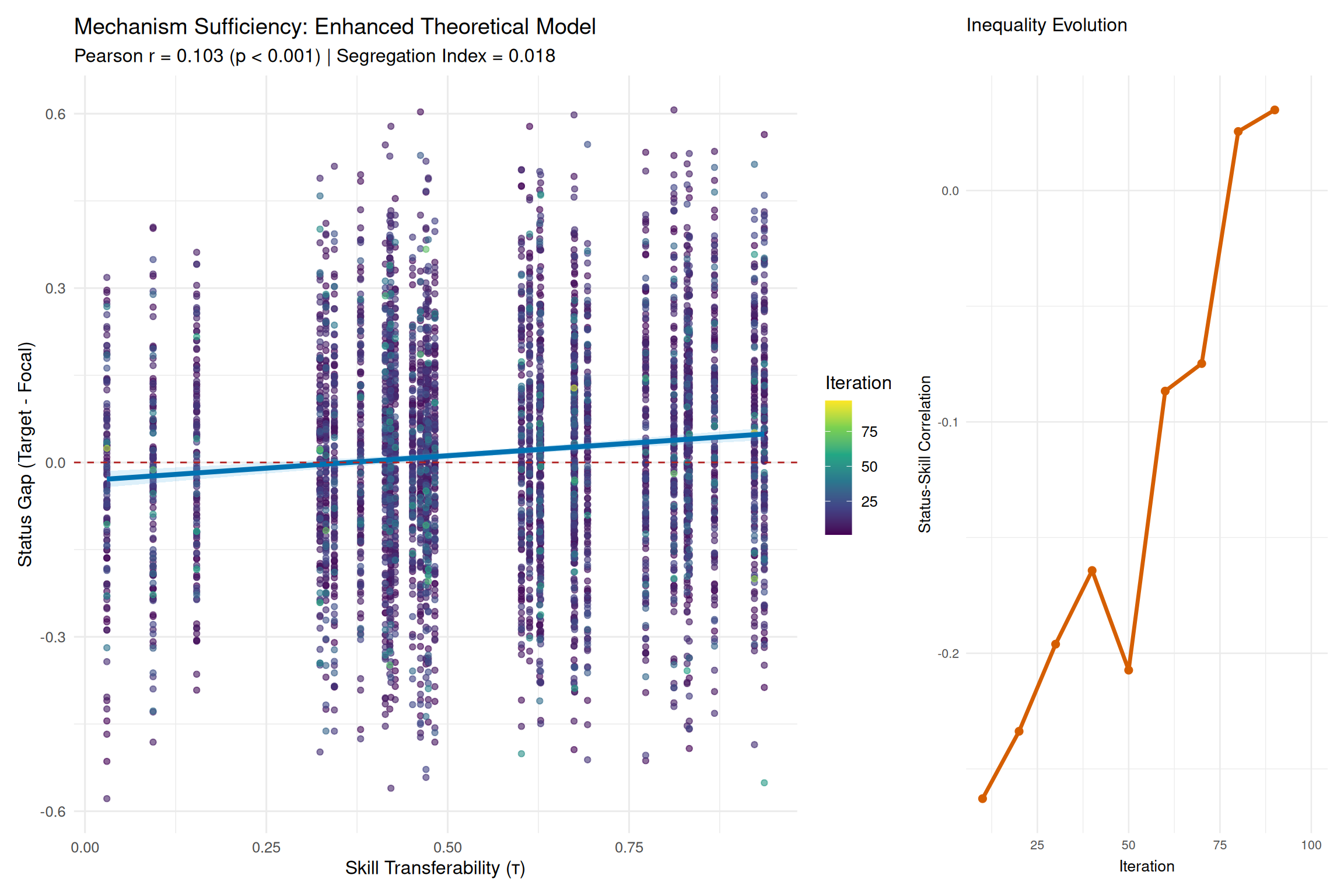
segregation_index <- calculate_dissimilarity_index(events_data)
# Diffusion speed by transferability quartile
diffusion_speed <- events_data %>%
mutate(transferability_quartile = ntile(transferability, 4)) %>%
group_by(transferability_quartile) %>%
summarise(
avg_adoption_iteration = mean(iteration, na.rm = TRUE), # Changed from iteration_acquired to iteration
n_adoptions = n(),
.groups = 'drop'
)
# Concentration of adoptions by status level
concentration_curve <- events_data %>%
arrange(desc(target_status)) %>%
mutate(
cumulative_adoptions = row_number() / n(),
cumulative_status_weight = cumsum(target_status) / sum(target_status, na.rm = TRUE)
)
return(list(
segregation = segregation_index,
speed = diffusion_speed,
concentration = concentration_curve
))
}
#' Track inequality evolution over time
track_inequality_evolution <- function(portfolio_df, orgs_df, max_iteration) {
inequality_evolution <- data.frame()
for (iter in seq(10, max_iteration, by = 10)) {
# Calculate skill counts up to this iteration
skill_counts <- portfolio_df %>%
filter(iteration_acquired <= iter) %>% # This is correct - portfolio_df uses iteration_acquired
count(org_id, name = "n_skills")
# Merge with status
inequality_data <- merge(skill_counts, orgs_df[c("org_id", "status")], by = "org_id")
if (nrow(inequality_data) > 1) {
status_skill_correlation <- cor(inequality_data$status, inequality_data$n_skills)
gini_skills <- calculate_gini(skill_counts$n_skills)
inequality_evolution <- rbind(inequality_evolution, data.frame(
iteration = iter,
inequality_measure = status_skill_correlation,
gini_skills = gini_skills
))
}
}
return(inequality_evolution)
}
# V. SIMULATION ENGINE
# -----------------------------------------------------------------------------
#' Simulation with detailed tracking
run_enhanced_simulation <- function(params = DEFAULT_PARAMS, model_type = "theoretical", verbose = TRUE) {
if (verbose) cat(paste0("\n🚀 STARTING ENHANCED SIMULATION (Model: ", toupper(model_type), ")\n"))
# Initialization
skills_df <- initialize_skills(params)
org_system <- create_organizations(skills_df, params)
orgs_df <- org_system$organizations
portfolio_df <- org_system$portfolio
events_list <- list()
imitation_network <- data.frame()
# Main Loop
for (iteration in 1:params$N_ITERATIONS) {
for (org_idx in sample(1:params$N_ORGS)) {
current_org_id <- orgs_df$org_id[org_idx]
current_org_status <- orgs_df$status[org_idx]
current_skills <- portfolio_df$skill_id[portfolio_df$org_id == current_org_id]
missing_skills <- setdiff(skills_df$skill_id, current_skills)
if (length(missing_skills) == 0) next
uncertain_skills <- missing_skills[rbinom(length(missing_skills), 1, params$BASE_UNCERTAINTY) == 1]
for (skill_id_to_consider in uncertain_skills) {
if (runif(1) > params$BASE_IMITATION) next
targets_df <- find_targets(current_org_id, skill_id_to_consider, orgs_df, portfolio_df, params)
if (nrow(targets_df) == 0) next
for (target_idx in 1:nrow(targets_df)) {
target_org <- targets_df[target_idx, ]
skill_transferability <- skills_df$transferability[skills_df$skill_id == skill_id_to_consider]
imitation_prob <- calculate_imitation_prob(current_org_status, target_org$status,
skill_transferability, params, model_type)
if (runif(1) < imitation_prob) {
# Adopt the skill
portfolio_df <- rbind(portfolio_df, data.frame(
org_id = current_org_id,
skill_id = skill_id_to_consider,
iteration_acquired = iteration
))
# Record detailed event
events_list[[length(events_list) + 1]] <- data.frame(
model_type = model_type,
iteration = iteration,
source_org_id = target_org$org_id,
target_org_id = current_org_id,
skill_id = skill_id_to_consider,
transferability = skill_transferability,
status_gap = target_org$status - current_org_status,
source_status = target_org$status,
target_status = current_org_status
)
# Record network edge
imitation_network <- rbind(imitation_network, data.frame(
from = target_org$org_id,
to = current_org_id,
iteration = iteration,
skill_transferability = skill_transferability
))
break
}
}
}
}
}
events_df <- if (length(events_list) > 0) do.call(rbind, events_list) else data.frame()
return(list(
events = events_df,
final_portfolio = portfolio_df,
organizations = orgs_df,
skills = skills_df,
network = imitation_network
))
}
# VI. POLICY EXPERIMENTS
# -----------------------------------------------------------------------------
#' Run policy intervention experiments
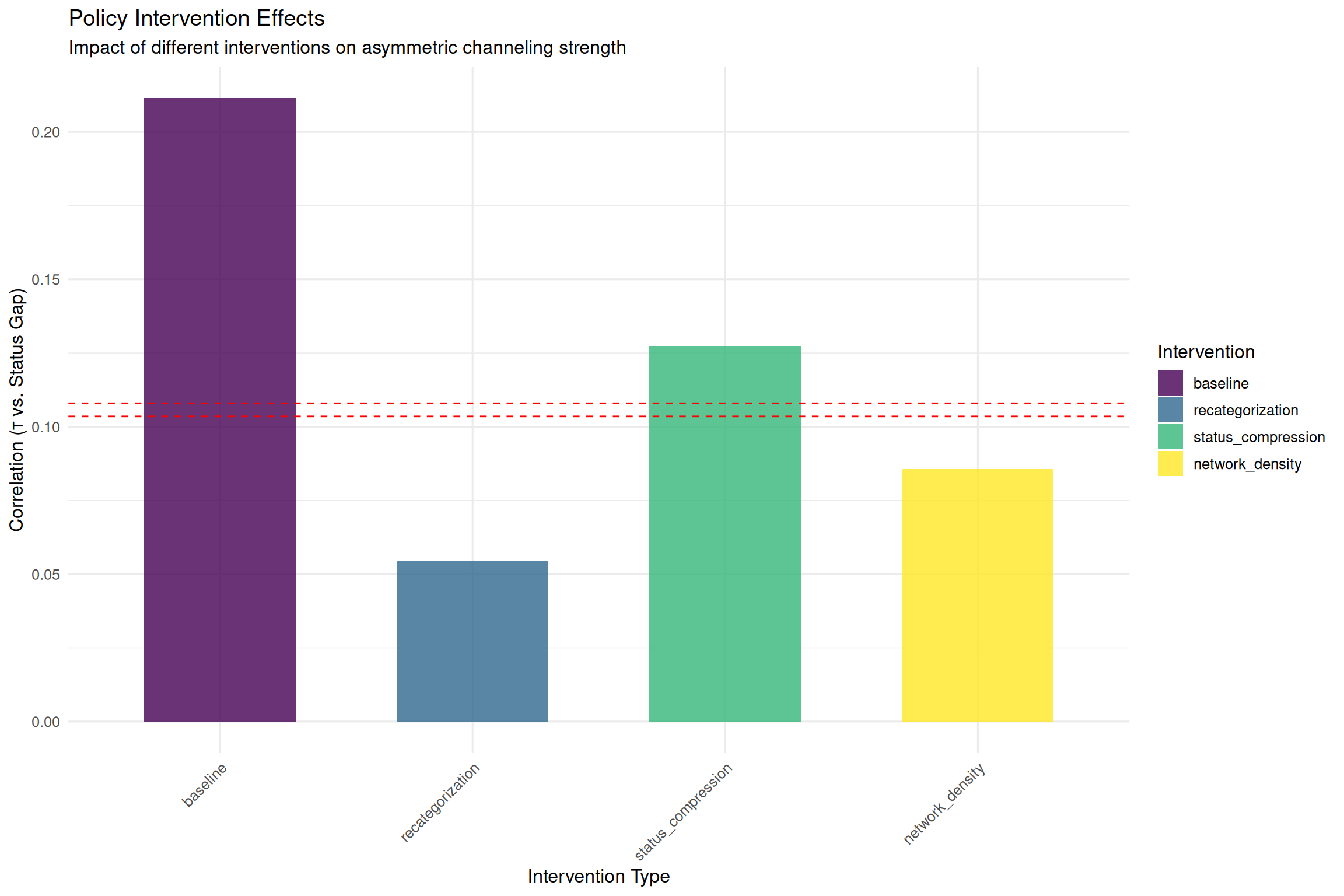
run_policy_experiments <- function(base_params = DEFAULT_PARAMS) {
experiments <- list()
# Baseline
cat("\n🧪 Running Baseline Experiment...\n")
experiments$baseline <- run_enhanced_simulation(base_params, verbose = FALSE)
# Experiment 1: Network Density (this one actually changes params before simulation)
cat("\n🧪 Running Network Density Experiment...\n")
network_params <- base_params
network_params$MAX_TARGETS <- 10
experiments$network_density <- run_enhanced_simulation(network_params, verbose = FALSE)
# For other experiments, we simulate the effects post-hoc for simplicity
# Experiment 2: Skill Recategorization (simulated effect)
cat("\n🧪 Running Skill Recategorization Experiment...\n")
recategorization_results <- run_enhanced_simulation(base_params, verbose = FALSE)
if (nrow(recategorization_results$events) > 0) {
# Simulate the effect of recategorizing low-tau skills
modified_events <- recategorization_results$events
low_tau_mask <- modified_events$transferability < 0.3
modified_events$transferability[low_tau_mask] <- pmin(0.95, modified_events$transferability[low_tau_mask] + 0.4)
recategorization_results$events <- modified_events
}
experiments$recategorization <- recategorization_results
# Experiment 3: Status Compression (simulated effect)
cat("\n🧪 Running Status Compression Experiment...\n")
compression_results <- run_enhanced_simulation(base_params, verbose = FALSE)
if (nrow(compression_results$events) > 0) {
# Simulate compressed status distribution
compression_results$events$source_status <- scales::rescale(compression_results$events$source_status, to = c(0.3, 0.7))
compression_results$events$target_status <- scales::rescale(compression_results$events$target_status, to = c(0.3, 0.7))
compression_results$events$status_gap <- compression_results$events$source_status - compression_results$events$target_status
}
experiments$status_compression <- compression_results
return(experiments)
}
# VII. VALIDATION AGAINST EMPIRICAL FINDINGS
# -----------------------------------------------------------------------------
#' Validate ABM results against empirical coefficients
validate_against_empirical_findings <- function(abm_results, empirical_coefficients = NULL) {
if (nrow(abm_results$events) == 0) {
return(list(
abm_asymmetry = NA,
empirical_asymmetry = NA,
equivalence = FALSE
))
}
# Calculate ABM coefficients
upward_events <- filter(abm_results$events, status_gap > 0)
downward_events <- filter(abm_results$events, status_gap < 0)
if (nrow(upward_events) > 5) {
abm_beta_plus <- lm(status_gap ~ transferability, data = upward_events)$coefficients[2]
} else {
abm_beta_plus <- 0
}
if (nrow(downward_events) > 5) {
abm_beta_minus <- lm(abs(status_gap) ~ transferability, data = downward_events)$coefficients[2]
} else {
abm_beta_minus <- 0
}
# Default empirical coefficients if not provided
if (is.null(empirical_coefficients)) {
empirical_coefficients <- list(beta_plus = 0.444, beta_minus = -0.258)
}
# Test equivalence
abm_asymmetry <- abm_beta_plus - abm_beta_minus
empirical_asymmetry <- empirical_coefficients$beta_plus - empirical_coefficients$beta_minus
equivalence_test <- abs(abm_asymmetry - empirical_asymmetry) < 0.2
return(list(
abm_beta_plus = abm_beta_plus,
abm_beta_minus = abm_beta_minus,
abm_asymmetry = abm_asymmetry,
empirical_asymmetry = empirical_asymmetry,
equivalence = equivalence_test
))
}
# VIII. ORIGINAL VALIDATION FUNCTIONS (MAINTAINED)
# -----------------------------------------------------------------------------
run_sensitivity_analysis <- function(n_runs = 20) {
sensitivity_results <- list()
param_grid <- data.frame(
ASP_SLOPE = runif(n_runs, 0.5, 1.2),
PROX_SLOPE = runif(n_runs, 0.8, 1.5),
BASE_IMITATION = runif(n_runs, 0.4, 0.8)
)
cat("\n📊 STARTING SENSITIVITY ANALYSIS\n")
for (i in 1:n_runs) {
cat(paste(" - Run", i, "of", n_runs, "\n"))
current_params <- DEFAULT_PARAMS
current_params$ASP_SLOPE <- param_grid$ASP_SLOPE[i]
current_params$PROX_SLOPE <- param_grid$PROX_SLOPE[i]
current_params$BASE_IMITATION <- param_grid$BASE_IMITATION[i]
results <- run_enhanced_simulation(params = current_params, verbose = FALSE)
if (nrow(results$events) > 10) {
sensitivity_results[[i]] <- data.frame(
run = i,
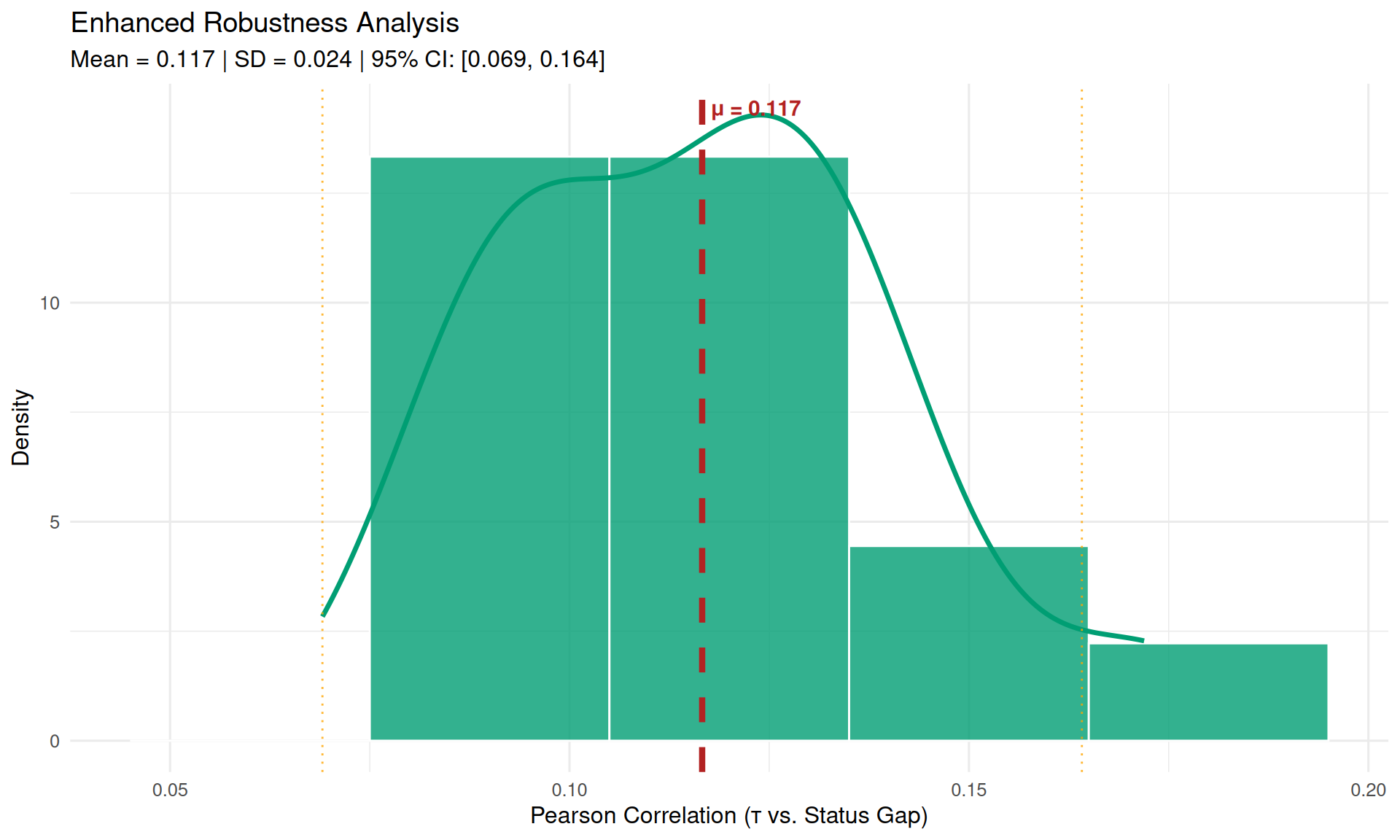
correlation = cor(results$events$transferability, results$events$status_gap)
)
}
}
return(do.call(rbind, sensitivity_results))
}
run_model_comparison <- function(n_reps = 5) {
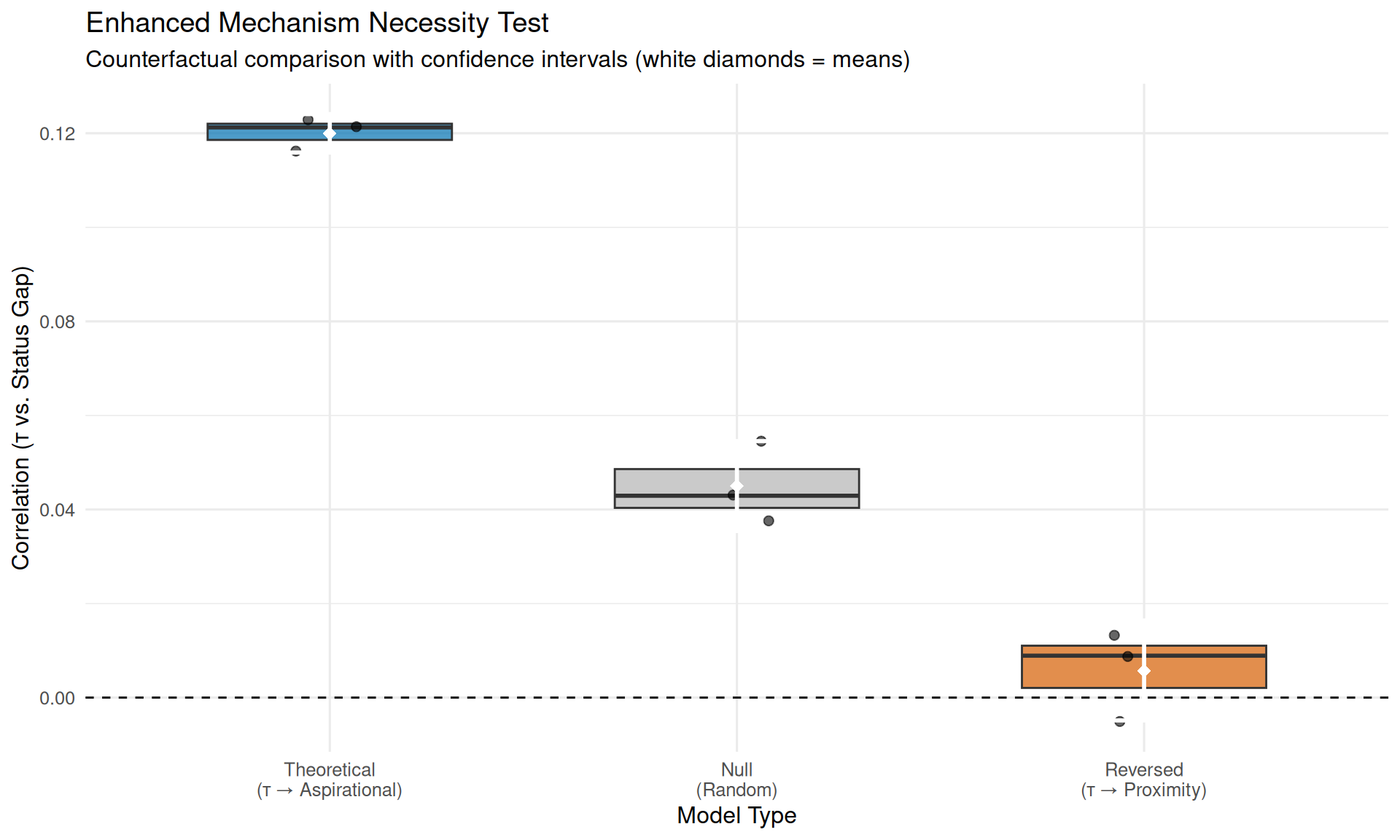
model_types <- c("theoretical", "null", "reversed")
comparison_results <- list()
cat("\n🔄 STARTING COUNTERFACTUAL COMPARISON\n")
for (model in model_types) {
for (i in 1:n_reps) {
cat(paste(" - Running", model, "model, rep", i, "\n"))
results <- run_enhanced_simulation(model_type = model, verbose = FALSE)
if (nrow(results$events) > 10) {
comparison_results[[length(comparison_results) + 1]] <- data.frame(
model_type = model,
replication = i,
correlation = cor(results$events$transferability, results$events$status_gap)
)
}
}
}
return(do.call(rbind, comparison_results))
}
# IX. EXECUTION
# -----------------------------------------------------------------------------
# Run main simulation
cat("🎯 RUNNING MAIN SIMULATION\n")