# Cargamos los paquetes necesarios usando pacman
# pacman nos permite instalar y cargar paquetes en un solo paso
pacman::p_load(
tidyverse, # Conjunto de paquetes para manipulación y visualización
ggthemes, # Temas adicionales para hacer gráficos más atractivos
viridis, # Paletas de colores accesibles y visualmente agradables
hrbrthemes, # Temas modernos de alta calidad
patchwork, # Permite combinar múltiples gráficos fácilmente
scales, # Herramientas para personalizar escalas en gráficos
ggraph, # Extensión de ggplot2 para grafos y redes
tidygraph, # Manipulación de datos de redes al estilo tidyverse
plotly, # Para hacer gráficos interactivos
kableExtra, # Para crear tablas bonitas en R Markdown
ggmosaic,
ggalluvial
)
# Configuramos un tema global para consistencia en nuestros gráficos
theme_set(theme_minimal(base_size = 12))1. Introducción
Esta guía está diseñada para ayudarte a comprender y crear visualizaciones efectivas de datos categóricos usando R. Aprenderemos desde gráficos básicos hasta visualizaciones avanzadas, explicando cada paso del proceso.
1.1 Configuración del Entorno
Primero, configuraremos nuestro entorno de trabajo cargando los paquetes necesarios. Cada paquete tiene un propósito específico en nuestro flujo de trabajo:
2. Visualizaciones Básicas Mejoradas
2.1 Gráfico de Barras Avanzado
Los gráficos de barras son fundamentales para visualizar datos categóricos. Aquí aprenderemos a crear uno con características avanzadas:
# Creamos datos de ejemplo estructurados
# Este es un ejemplo común en análisis de datos categóricos
datos_categoricos <- tibble(
categoria = LETTERS[1:6], # Usamos las primeras 6 letras del alfabeto
valor = c(25, 40, 15, 30, 20, 35), # Valores para cada categoría
grupo = rep(c("Grupo 1", "Grupo 2"), each = 3) # Agrupación de categorías
) %>%
# Convertimos categoria a factor para mejor control del orden
mutate(categoria = factor(categoria))
# Creamos el gráfico paso a paso
ggplot(datos_categoricos,
aes(x = fct_reorder(categoria, valor), # Ordenamos por valor
y = valor,
fill = grupo)) + # Color según grupo
# Añadimos las barras
geom_bar(stat = "identity", # Usamos los valores directamente
position = "dodge", # Barras lado a lado
alpha = 0.8, # Transparencia
width = 0.7) + # Ancho de las barras
# Añadimos etiquetas de valor
geom_text(aes(label = valor),
position = position_dodge(width = 0.7),
vjust = -0.5) +
# Usamos una escala de colores accesible
scale_fill_viridis_d() +
# Añadimos títulos y etiquetas
labs(title = "Distribución por Categorías",
subtitle = "Comparación entre grupos con valores exactos",
x = "Categoría",
y = "Valor",
fill = "Grupo") +
# Aplicamos un tema moderno
theme_ipsum_rc() +
# Personalizamos elementos del tema
theme(
axis.title = element_text(face = "bold"),
plot.title = element_text(size = 16, face = "bold"),
legend.position = "top"
)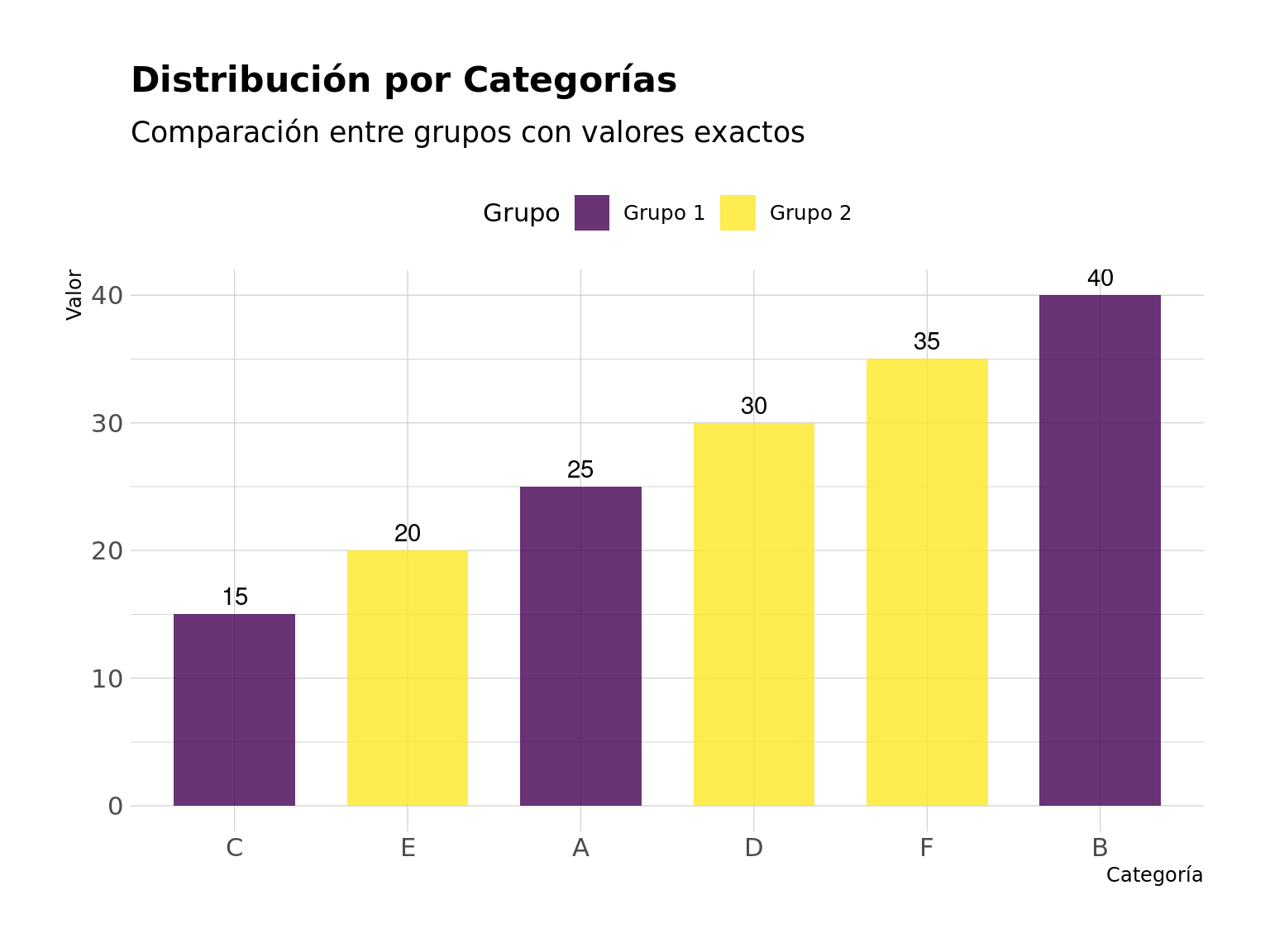
En este gráfico, hemos implementado varias características importantes:
- Ordenamiento: Usamos
fct_reorder()para ordenar las categorías por valor
- Ordenamiento: Usamos
- Agrupación: Separamos las barras por grupos usando
position = "dodge"
- Agrupación: Separamos las barras por grupos usando
- Etiquetas: Añadimos valores exactos sobre cada barra
- Accesibilidad: Utilizamos la paleta viridis para mejor visibilidad
- Diseño: Aplicamos un tema moderno y limpio
2.2 Visualización de Redes con ggraph
Ahora crearemos una visualización de red usando ggraph, que es más flexible y consistente con la gramática de ggplot2:
# Creamos datos para la red
# Primero los nodos
nodos <- tibble(
id = 1:8,
tipo = rep(c("A", "B"), each = 4),
tamaño = sample(10:30, 8)
)
# Luego las conexiones
enlaces <- tibble(
from = sample(1:8, 10, replace = TRUE),
to = sample(1:8, 10, replace = TRUE),
peso = runif(10, 0.1, 1)
) %>%
# Evitamos auto-conexiones
filter(from != to)
# Creamos el objeto de grafo
grafo <- tbl_graph(nodes = nodos, edges = enlaces)
# Creamos la visualización
ggraph(grafo, layout = "stress") +
# Añadimos las conexiones
geom_edge_link(aes(width = peso, alpha = peso),
color = "gray50") +
# Añadimos los nodos
geom_node_point(aes(size = tamaño,
color = tipo),
alpha = 0.8) +
# Añadimos etiquetas a los nodos
geom_node_text(aes(label = id),
repel = TRUE) +
# Personalizamos la apariencia
scale_edge_width(range = c(0.2, 2)) +
scale_size(range = c(4, 10)) +
scale_color_viridis_d() +
# Ajustamos el tema
theme_graph() +
# Añadimos títulos
labs(title = "Red de Relaciones Categóricas",
subtitle = "Visualización con ggraph",
color = "Tipo",
size = "Tamaño",
edge_width = "Peso de conexión")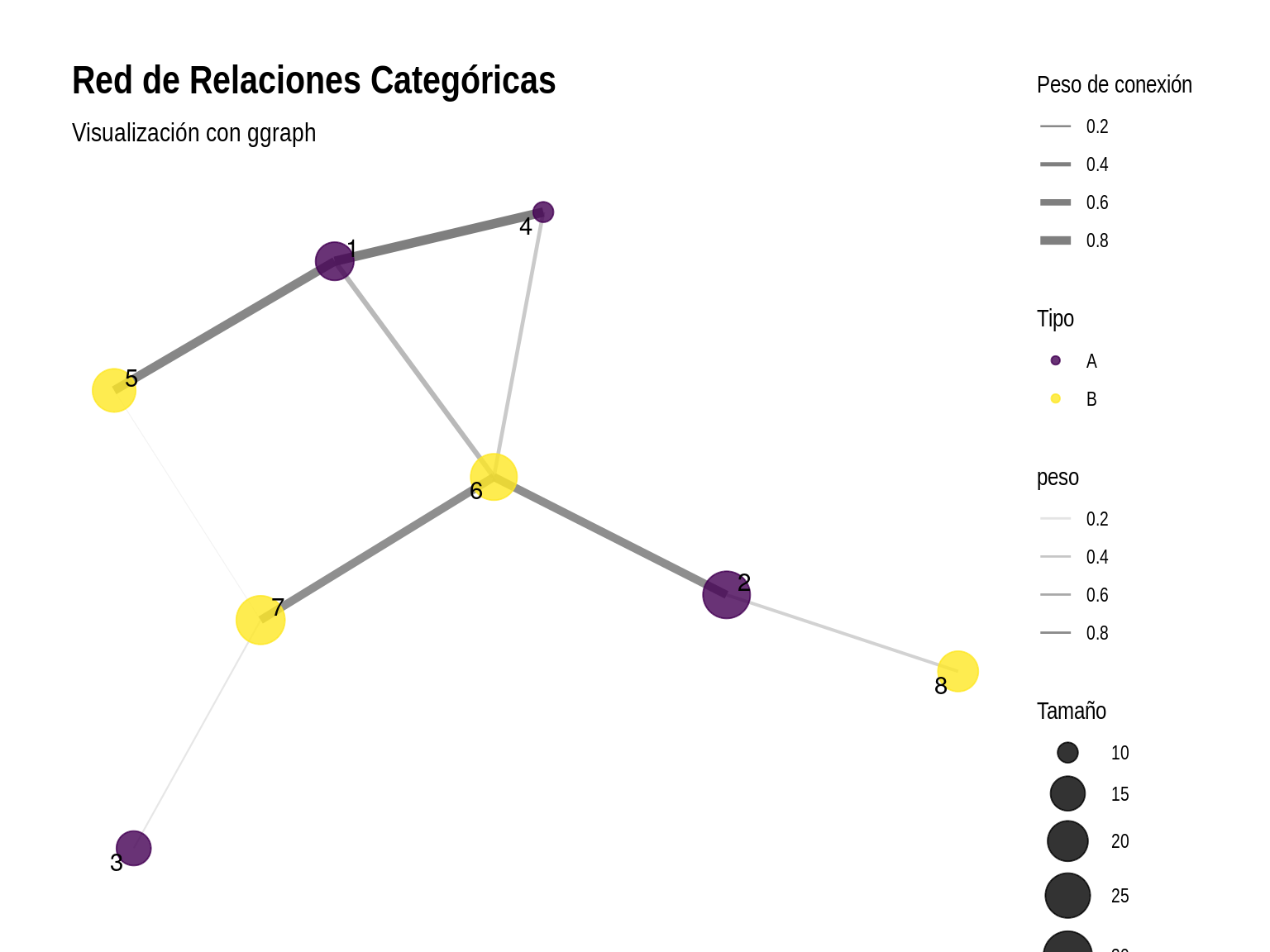
Esta visualización de red demuestra:
- Estructura: Representamos relaciones entre entidades
- Atributos múltiples: Mostramos tipo, tamaño y peso de conexiones
- Diseño: Utilizamos un layout que optimiza la visualización
- Estética: Implementamos transparencia y variación en grosor de líneas
2.3 Gráficos de Mosaico Avanzados
Los gráficos de mosaico son excelentes para visualizar relaciones entre variables categóricas. Son particularmente útiles cuando queremos mostrar proporciones y dependencias:
# Primero, creamos datos más significativos
set.seed(123) # Para reproducibilidad
datos_mosaico <- tibble(
nivel_educativo = sample(c("Básica", "Media", "Superior"), 1000,
prob = c(0.3, 0.4, 0.3), replace = TRUE),
grupo_edad = sample(c("18-25", "26-35", "36+"), 1000,
prob = c(0.4, 0.35, 0.25), replace = TRUE),
genero = sample(c("F", "M"), 1000, replace = TRUE)
)
# Creamos el gráfico de mosaico
ggplot(datos_mosaico) +
# Usamos geom_mosaic para crear el mosaico
geom_mosaic(aes(x = product(nivel_educativo, grupo_edad),
fill = genero)) +
# Personalizamos colores
scale_fill_viridis_d(option = "D") +
# Añadimos títulos y etiquetas
labs(title = "Distribución Educativa por Edad y Género",
subtitle = "Visualización mediante gráfico de mosaico",
fill = "Género") +
# Personalizamos el tema
theme_minimal() +
theme(
axis.text.x = element_text(angle = 45, hjust = 1),
plot.title = element_text(face = "bold", size = 14),
plot.subtitle = element_text(size = 11, color = "gray30"),
panel.grid = element_blank()
)Warning: The `scale_name` argument of `continuous_scale()` is deprecated as of ggplot2
3.5.0.Warning: The `trans` argument of `continuous_scale()` is deprecated as of ggplot2 3.5.0.
ℹ Please use the `transform` argument instead.Warning: `unite_()` was deprecated in tidyr 1.2.0.
ℹ Please use `unite()` instead.
ℹ The deprecated feature was likely used in the ggmosaic package.
Please report the issue at <https://github.com/haleyjeppson/ggmosaic>.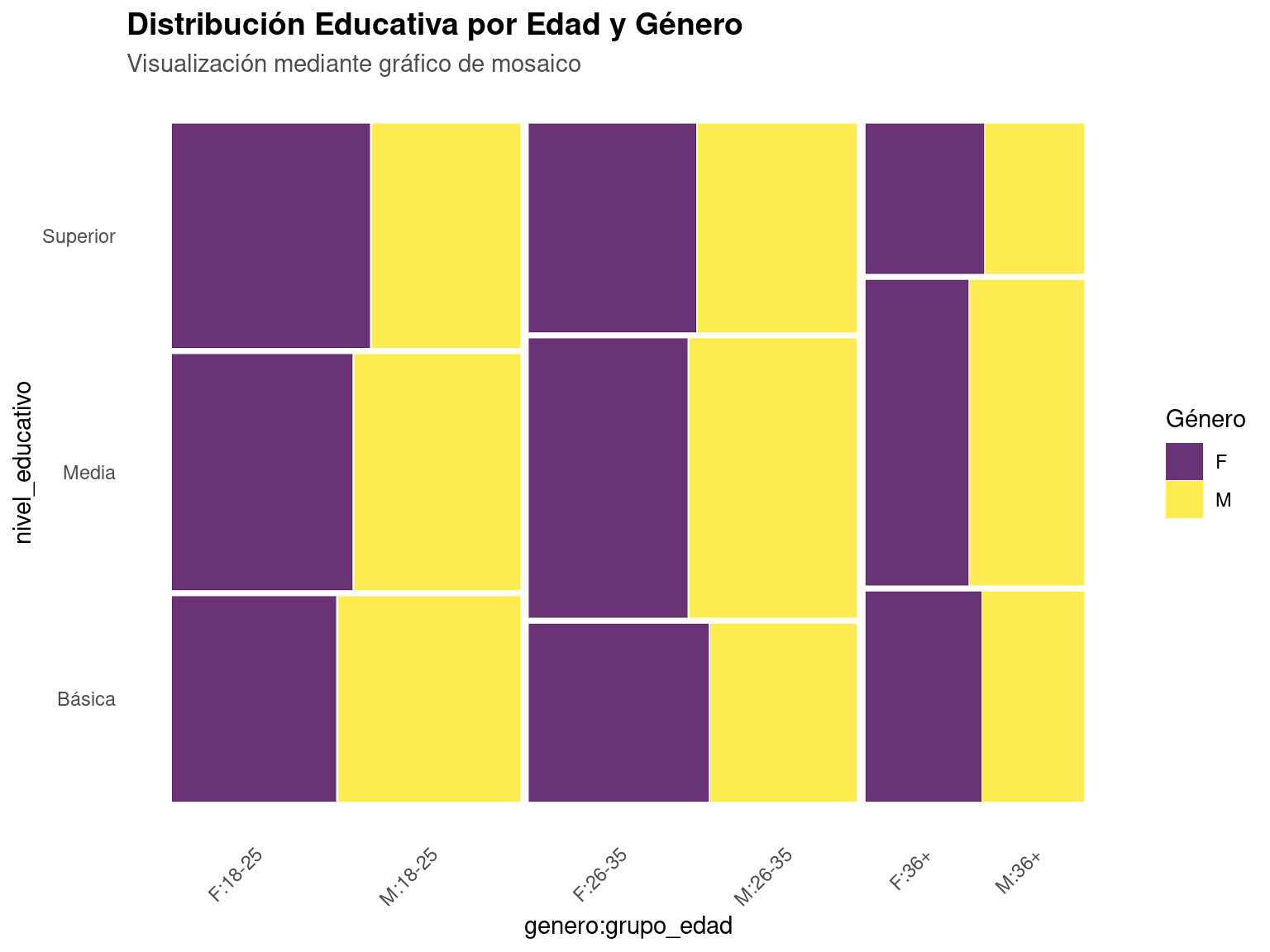
# Añadimos una tabla resumen para complementar el gráfico
datos_mosaico %>%
group_by(nivel_educativo, grupo_edad, genero) %>%
summarise(n = n()) %>%
spread(genero, n) %>%
kable(caption = "Distribución de frecuencias") %>%
kable_styling(bootstrap_options = c("striped", "hover"))`summarise()` has grouped output by 'nivel_educativo', 'grupo_edad'. You can
override using the `.groups` argument.| nivel_educativo | grupo_edad | F | M |
|---|---|---|---|
| Básica | 18-25 | 57 | 63 |
| Básica | 26-35 | 54 | 44 |
| Básica | 36+ | 41 | 36 |
| Media | 18-25 | 72 | 66 |
| Media | 26-35 | 75 | 79 |
| Media | 36+ | 53 | 59 |
| Superior | 18-25 | 75 | 56 |
| Superior | 26-35 | 59 | 56 |
| Superior | 36+ | 30 | 25 |
Gráfico de mosaico mostrando relaciones entre variables categóricas
¿Por qué usar gráficos de mosaico?
- Muestran proporciones relativas entre categorías
- Permiten visualizar hasta 3-4 variables categóricas simultáneamente
- Son efectivos para identificar patrones de asociación
2.4 Heatmaps Categóricos Interactivos
Los heatmaps son ideales para visualizar relaciones entre categorías cuando tenemos una medida de intensidad:
# Creamos datos más significativos
datos_heat <- expand_grid(
departamento = c("Ventas", "Marketing", "IT", "RRHH", "Finanzas"),
trimestre = c("Q1", "Q2", "Q3", "Q4")
) %>%
mutate(
rendimiento = rnorm(n(), mean = 75, sd = 15),
categoria_rendimiento = case_when(
rendimiento < 60 ~ "Bajo",
rendimiento < 80 ~ "Medio",
TRUE ~ "Alto"
)
)
# Creamos el heatmap base con ggplot2
p <- ggplot(datos_heat,
aes(x = trimestre,
y = departamento,
fill = rendimiento,
text = paste("Departamento:", departamento,
"\nTrimestre:", trimestre,
"\nRendimiento:", round(rendimiento, 1)))) +
geom_tile(color = "white") +
# Usamos una escala divergente
scale_fill_viridis(option = "D") +
# Personalizamos la apariencia
labs(title = "Rendimiento por Departamento y Trimestre",
x = "Trimestre",
y = "Departamento",
fill = "Rendimiento") +
theme_minimal() +
theme(
axis.text = element_text(face = "bold"),
panel.grid = element_blank(),
legend.position = "right"
)
# Convertimos a interactivo
ggplotly(p, tooltip = "text")Heatmap interactivo de relaciones categóricas
# Explicación del patrón observado
datos_heat %>%
group_by(departamento) %>%
summarise(
rendimiento_medio = mean(rendimiento),
variabilidad = sd(rendimiento)
) %>%
arrange(desc(rendimiento_medio)) %>%
kable(caption = "Resumen de rendimiento por departamento",
digits = 2) %>%
kable_styling(bootstrap_options = c("striped", "hover"))| departamento | rendimiento_medio | variabilidad |
|---|---|---|
| Marketing | 85.27 | 18.98 |
| RRHH | 82.99 | 9.06 |
| IT | 75.50 | 18.06 |
| Finanzas | 74.79 | 7.11 |
| Ventas | 69.74 | 10.55 |
Heatmap interactivo de relaciones categóricas
Elementos clave del heatmap:
- Color: Representa la intensidad o valor
- Posición: Dos dimensiones categóricas
- Interactividad: Tooltips para detalles específicos
- Resumen: Tabla complementaria para métricas clave
2.5 Visualización de Flujos con ggalluvial
Los diagramas de flujo (o aluviales) son excelentes para mostrar cambios en categorías a lo largo del tiempo o entre estados:
# Creamos datos de ejemplo de trayectorias profesionales
datos_flujo <- tibble(
id = rep(1:200, each = 3),
tiempo = rep(c("2020", "2021", "2022"), times = 200),
estado = c(
# 2020
sample(c("Estudiante", "Empleado", "Desempleado"), 200,
prob = c(0.5, 0.3, 0.2), replace = TRUE),
# 2021
sample(c("Estudiante", "Empleado", "Desempleado"), 200,
prob = c(0.3, 0.5, 0.2), replace = TRUE),
# 2022
sample(c("Estudiante", "Empleado", "Desempleado"), 200,
prob = c(0.2, 0.6, 0.2), replace = TRUE)
)
)
# Creamos el diagrama de flujo
ggplot(datos_flujo,
aes(x = tiempo,
stratum = estado,
alluvium = id,
fill = estado,
label = estado)) +
geom_flow(stat = "alluvium",
lode.guidance = "frontback",
alpha = 0.7) +
geom_stratum() +
# Añadimos etiquetas
geom_text(stat = "stratum",
aes(label = after_stat(n))) +
# Personalizamos colores y tema
scale_fill_viridis_d() +
theme_minimal() +
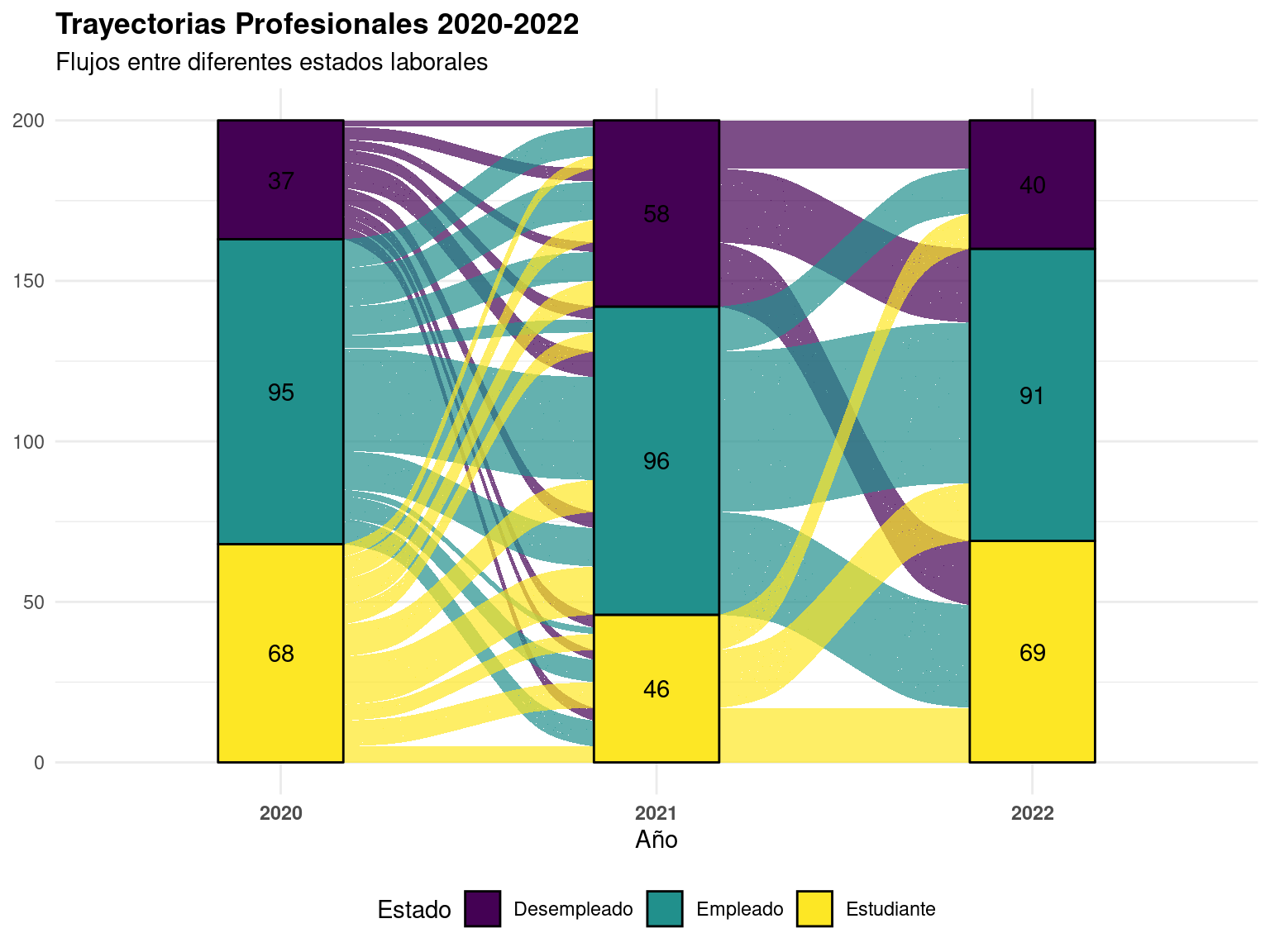
labs(title = "Trayectorias Profesionales 2020-2022",
subtitle = "Flujos entre diferentes estados laborales",
x = "Año",
fill = "Estado") +
theme(
legend.position = "bottom",
plot.title = element_text(face = "bold"),
axis.text.x = element_text(face = "bold")
)
# Añadimos una tabla de transiciones
datos_flujo %>%
group_by(tiempo, estado) %>%
summarise(n = n()) %>%
spread(tiempo, n) %>%
kable(caption = "Distribución por año") %>%
kable_styling(bootstrap_options = c("striped", "hover"))`summarise()` has grouped output by 'tiempo'. You can override using the
`.groups` argument.| estado | 2020 | 2021 | 2022 |
|---|---|---|---|
| Desempleado | 37 | 58 | 40 |
| Empleado | 95 | 96 | 91 |
| Estudiante | 68 | 46 | 69 |
Diagrama de flujo mostrando transiciones entre categorías
Ventajas de los diagramas de flujo:
- Muestran cambios y transiciones
- Permiten seguir trayectorias individuales
- Visualizan proporciones cambiantes
- Identifican patrones de movimiento
3. Visualizaciones de Distribución
3.1 Gráficos de Ridgeline para Categorías
Los gráficos de ridgeline son excelentes para comparar distribuciones entre categorías, especialmente cuando queremos ver cambios o patrones evolutivos:
# Cargamos ggridges
library(ggridges)
# Creamos datos más significativos
set.seed(123)
datos_distribuciones <- tibble(
año = rep(2018:2022, each = 1000),
valor = c(
rnorm(1000, mean = 20, sd = 5), # 2018
rnorm(1000, mean = 22, sd = 5), # 2019
rnorm(1000, mean = 18, sd = 6), # 2020
rnorm(1000, mean = 25, sd = 4), # 2021
rnorm(1000, mean = 28, sd = 5) # 2022
),
categoria = factor(año)
)
# Creamos el gráfico de ridgeline
ggplot(datos_distribuciones,
aes(x = valor,
y = categoria,
fill = after_stat(x))) +
geom_density_ridges_gradient(
scale = 3,
rel_min_height = 0.01,
gradient_lwd = 1
) +
scale_fill_viridis_c(option = "C") +
labs(
title = "Evolución de Distribuciones por Año",
subtitle = "Visualización mediante gráfico de ridgeline",
x = "Valor",
y = "Año",
fill = "Valor"
) +
theme_ridges() +
theme(
legend.position = "none",
plot.title = element_text(face = "bold"),
plot.subtitle = element_text(color = "gray40")
)Picking joint bandwidth of 1.11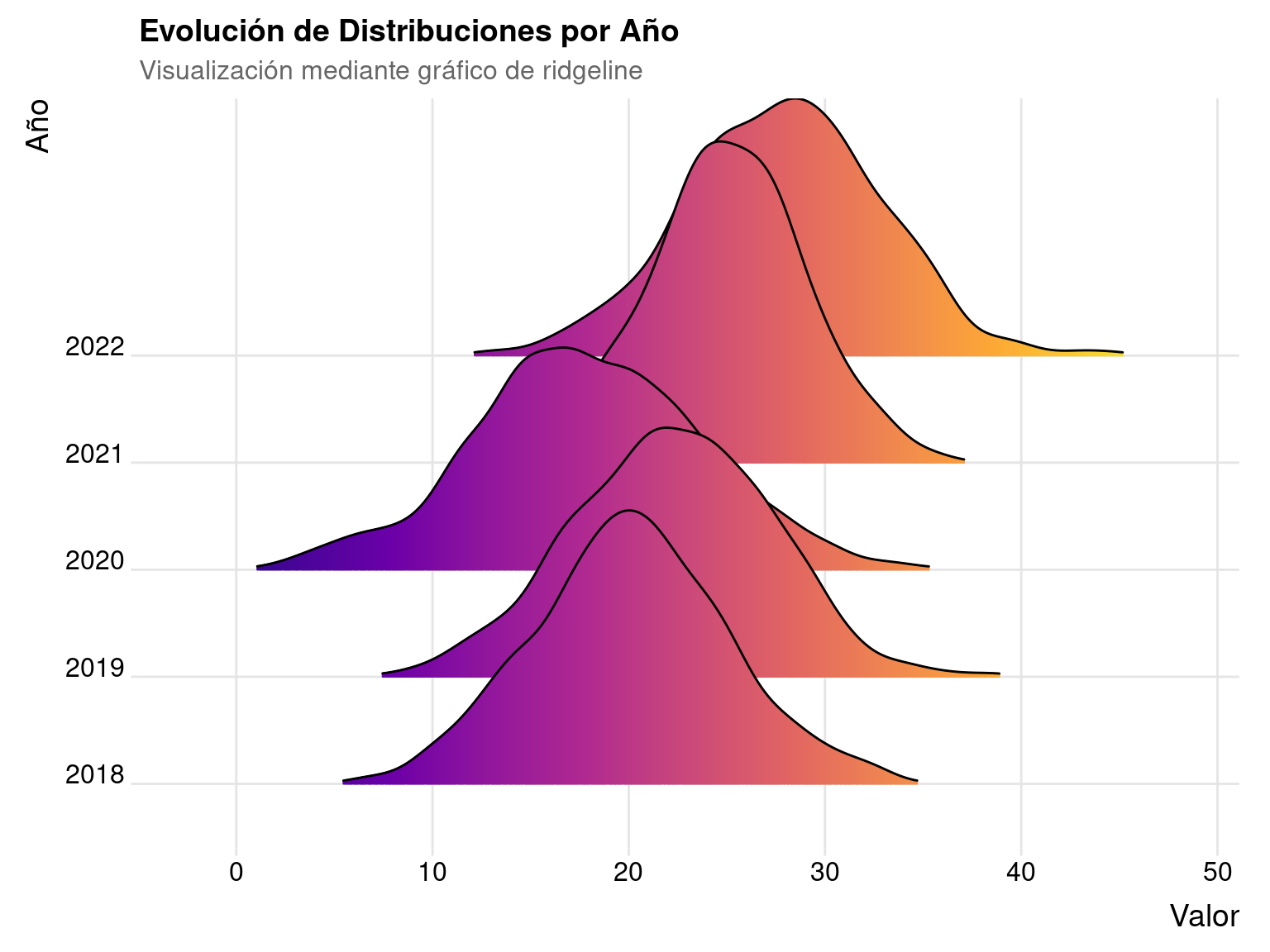
# Añadimos estadísticas descriptivas
datos_distribuciones %>%
group_by(año) %>%
summarise(
media = mean(valor),
desv_est = sd(valor),
mediana = median(valor),
q25 = quantile(valor, 0.25),
q75 = quantile(valor, 0.75)
) %>%
kable(caption = "Estadísticas descriptivas por año",
digits = 2) %>%
kable_styling(bootstrap_options = c("striped", "hover"))| año | media | desv_est | mediana | q25 | q75 |
|---|---|---|---|---|---|
| 2018 | 20.08 | 4.96 | 20.05 | 16.86 | 23.32 |
| 2019 | 22.21 | 5.05 | 22.27 | 18.73 | 25.77 |
| 2020 | 17.88 | 5.87 | 17.70 | 14.06 | 21.86 |
| 2021 | 24.96 | 3.97 | 24.97 | 22.44 | 27.60 |
| 2022 | 27.84 | 5.00 | 27.84 | 24.47 | 31.18 |
Gráfico de ridgeline mostrando distribuciones por categoría
¿Por qué usar gráficos ridgeline?
- Muestran la forma completa de la distribución
- Permiten comparar múltiples categorías
- Son efectivos para visualizar tendencias temporales
- Revelan cambios en la variabilidad
3.2 Visualizaciones Compuestas con Faceting
El faceting es una técnica poderosa para crear múltiples visualizaciones relacionadas:
# Creamos datos más complejos
datos_panel <- tibble(
departamento = rep(c("Ventas", "Marketing", "IT"), each = 300), # Reducimos a 300 cada uno
año = rep(rep(2020:2022, each = 100), 3), # Ahora coincide: 100 x 3 años x 3 departamentos = 900
rendimiento = c(
# Ventas (300 observaciones: 100 por año)
rnorm(100, 70, 10), rnorm(100, 75, 8), rnorm(100, 80, 12),
# Marketing (300 observaciones: 100 por año)
rnorm(100, 65, 12), rnorm(100, 72, 10), rnorm(100, 78, 9),
# IT (300 observaciones: 100 por año)
rnorm(100, 75, 8), rnorm(100, 82, 7), rnorm(100, 85, 6)
),
categoria = cut(rendimiento,
breaks = c(-Inf, 60, 75, Inf),
labels = c("Bajo", "Medio", "Alto"))
)
# Creamos visualización múltiple
p1 <- ggplot(datos_panel, aes(x = rendimiento, fill = departamento)) +
geom_density(alpha = 0.5) +
facet_wrap(~año) +
scale_fill_viridis_d() +
theme_minimal() +
labs(title = "Distribución de Rendimiento por Año",
x = "Rendimiento",
y = "Densidad")
p2 <- ggplot(datos_panel,
aes(x = factor(año), y = rendimiento, fill = departamento)) +
geom_boxplot(alpha = 0.7) +
scale_fill_viridis_d() +
theme_minimal() +
labs(title = "Boxplots de Rendimiento por Año y Departamento",
x = "Año",
y = "Rendimiento")
# Combinamos los gráficos con patchwork
p1 / p2 +
plot_annotation(
title = "Análisis Multidimensional del Rendimiento",
subtitle = "Distribuciones y comparaciones por departamento y año",
tag_levels = "A"
) &
theme(plot.title = element_text(face = "bold"))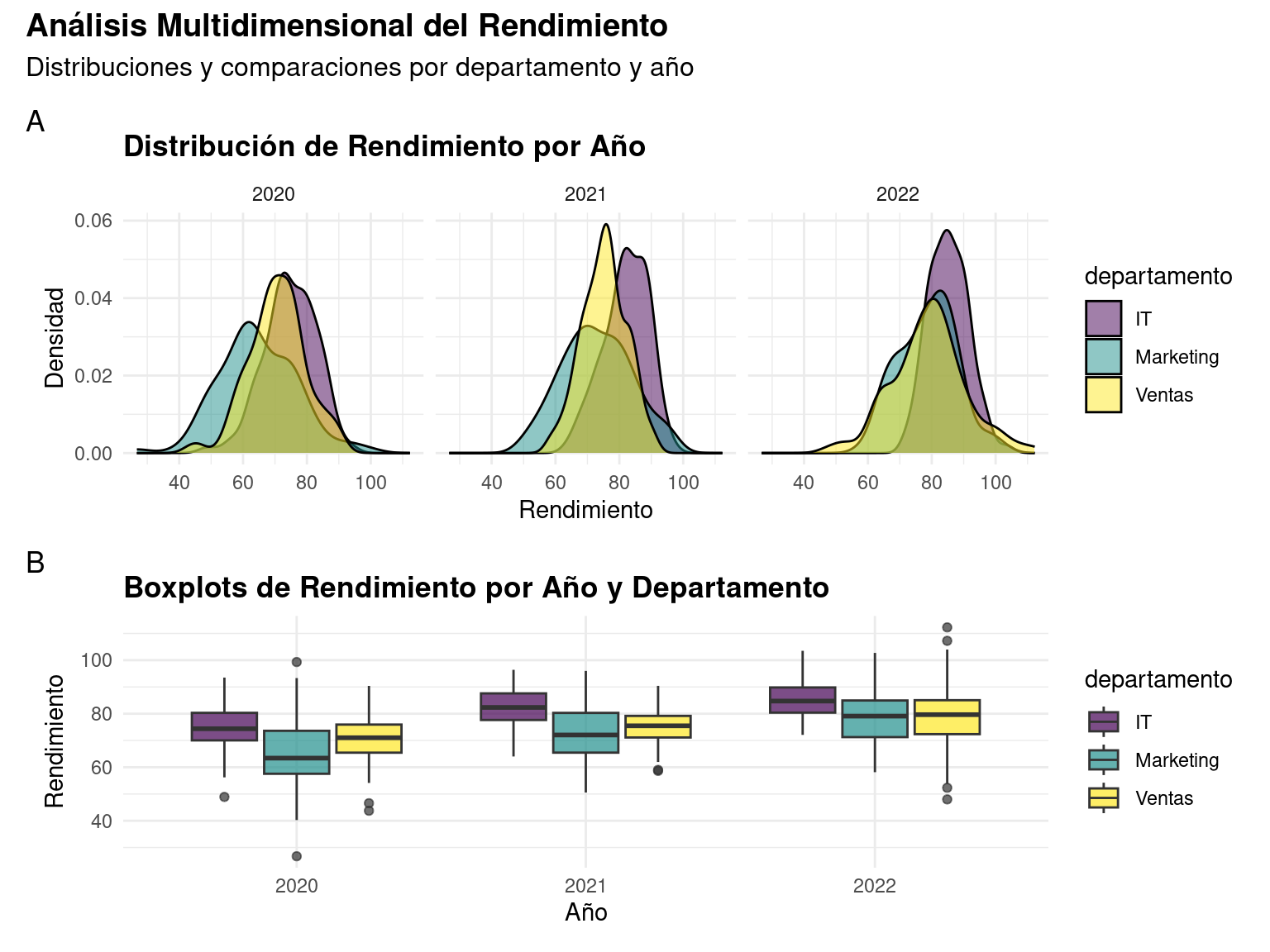
# Tabla resumen
datos_panel %>%
group_by(departamento, año) %>%
summarise(
n = n(),
media = mean(rendimiento),
mediana = median(rendimiento),
desv_est = sd(rendimiento),
prop_alto = mean(categoria == "Alto")
) %>%
kable(caption = "Métricas de rendimiento por departamento y año",
digits = 2) %>%
kable_styling(bootstrap_options = c("striped", "hover"))`summarise()` has grouped output by 'departamento'. You can override using the
`.groups` argument.| departamento | año | n | media | mediana | desv_est | prop_alto |
|---|---|---|---|---|---|---|
| IT | 2020 | 100 | 74.82 | 74.39 | 8.10 | 0.49 |
| IT | 2021 | 100 | 82.10 | 82.35 | 6.91 | 0.82 |
| IT | 2022 | 100 | 85.22 | 84.73 | 6.15 | 0.97 |
| Marketing | 2020 | 100 | 64.58 | 63.41 | 12.09 | 0.17 |
| Marketing | 2021 | 100 | 73.00 | 72.05 | 10.77 | 0.42 |
| Marketing | 2022 | 100 | 78.73 | 79.11 | 9.15 | 0.66 |
| Ventas | 2020 | 100 | 70.68 | 71.03 | 8.89 | 0.33 |
| Ventas | 2021 | 100 | 75.28 | 75.48 | 6.91 | 0.52 |
| Ventas | 2022 | 100 | 79.06 | 79.65 | 11.57 | 0.66 |
Panel de visualizaciones usando faceting
Elementos clave del faceting:
- Comparación: Facilita la comparación entre subgrupos
- Contexto: Mantiene la consistencia en escalas
- Patrones: Revela tendencias y diferencias
- Integración: Combina múltiples perspectivas
3.3 Gráficos de Waffle para Proporciones
Los gráficos de waffle son una alternativa interesante a los gráficos de pie para mostrar proporciones:
# Crear datos de proporciones
datos_proporcion <- datos_panel %>%
group_by(departamento, categoria) %>%
summarise(n = n()) %>%
mutate(prop = round(n/sum(n) * 100))`summarise()` has grouped output by 'departamento'. You can override using the
`.groups` argument.# Crear gráfico de waffle por departamento
waffle_plots <- datos_proporcion %>%
split(.$departamento) %>%
map(function(dept) {
waffle::waffle(
c(setNames(dept$prop, dept$categoria)),
rows = 10,
size = 0.5,
colors = viridis(3),
title = unique(dept$departamento)
)
})
# Combinar los gráficos
gridExtra::grid.arrange(
grobs = waffle_plots,
ncol = 3,
top = "Distribución de Categorías por Departamento"
)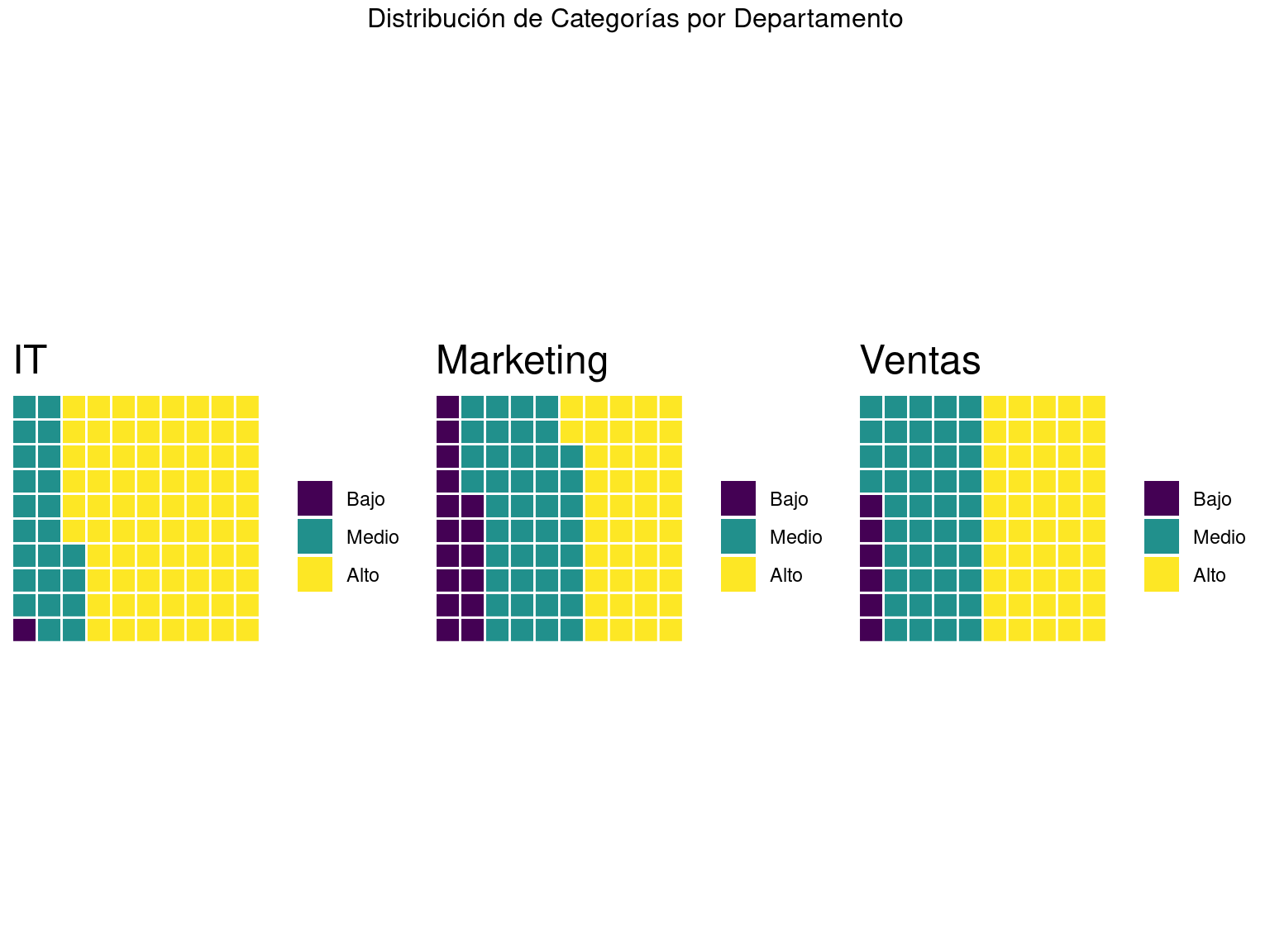
Ventajas de los gráficos de waffle:
- Representación intuitiva de porcentajes
- Fácil comparación entre categorías
- Visualización de partes de un todo
- Alternativa atractiva a gráficos circulares
4. Técnicas Avanzadas de Personalización
4.1 Temas Personalizados y Consistencia Visual
La consistencia visual es crucial en la visualización de datos. Aprenderemos a crear y aplicar temas personalizados:
# Creamos un tema personalizado
tema_personalizado <- theme_minimal() +
theme(
# Títulos
plot.title = element_text(
face = "bold",
size = 16,
margin = margin(b = 20)
),
plot.subtitle = element_text(
size = 12,
color = "gray40",
margin = margin(b = 10)
),
# Ejes
axis.title = element_text(
face = "bold",
size = 11
),
axis.text = element_text(
size = 10
),
# Leyenda
legend.position = "top",
legend.title = element_text(face = "bold"),
# Fondo y líneas de grilla
panel.grid.major = element_line(color = "gray90"),
panel.grid.minor = element_blank(),
# Márgenes
plot.margin = margin(20, 20, 20, 20)
)
# Creamos datos de ejemplo
datos_ejemplo <- tibble(
categoria = factor(rep(LETTERS[1:5], each = 3)),
subgrupo = rep(c("A", "B", "C"), 5),
valor = sample(20:100, 15)
)
# Aplicamos el tema a diferentes tipos de gráficos
p1 <- ggplot(datos_ejemplo,
aes(x = categoria, y = valor, fill = subgrupo)) +
geom_col(position = "dodge") +
scale_fill_viridis_d() +
labs(
title = "Gráfico de Barras con Tema Personalizado",
subtitle = "Ejemplo de consistencia visual",
x = "Categoría",
y = "Valor"
) +
tema_personalizado
p2 <- ggplot(datos_ejemplo,
aes(x = categoria, y = valor, color = subgrupo)) +
geom_point(size = 3) +
geom_line(aes(group = subgrupo)) +
scale_color_viridis_d() +
labs(
title = "Gráfico de Líneas con Tema Personalizado",
subtitle = "Manteniendo la consistencia visual",
x = "Categoría",
y = "Valor"
) +
tema_personalizado
# Mostramos los gráficos lado a lado
p1 / p2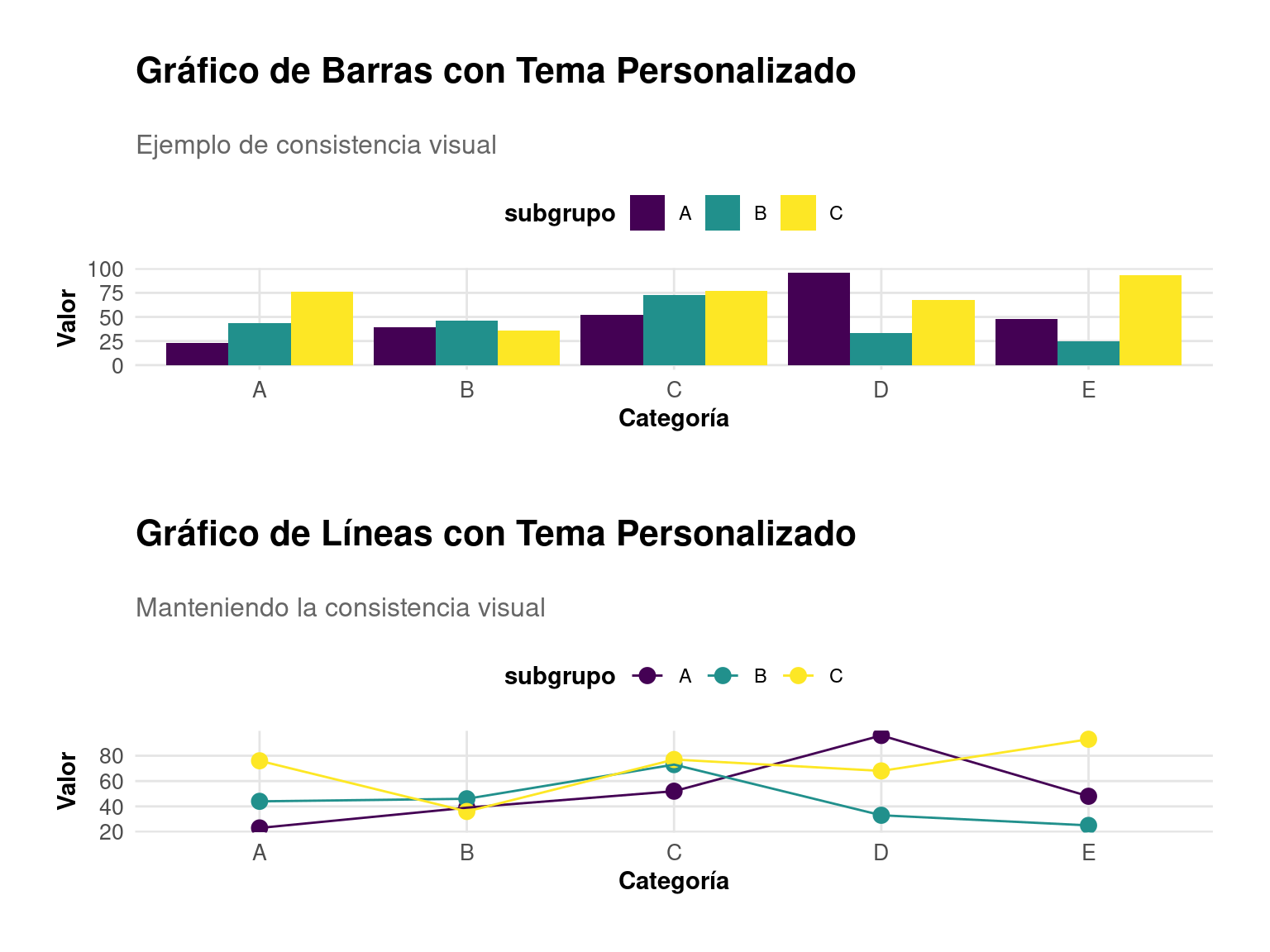
4.2 Anotaciones y Capas Personalizadas
Las anotaciones pueden mejorar significativamente la comprensión de nuestros gráficos:
# Creamos datos con puntos de interés
datos_tendencia <- tibble(
año = 2015:2022,
valor = c(45, 52, 58, 60, 85, 75, 90, 88),
evento = c("", "", "Cambio 1", "", "Máximo", "", "Tendencia", "")
)
# Creamos un gráfico con anotaciones
ggplot(datos_tendencia, aes(x = año, y = valor)) +
# Base del gráfico
geom_line(size = 1, color = "steelblue") +
geom_point(size = 3, color = "steelblue") +
# Añadimos anotaciones para puntos específicos
geom_segment(
data = datos_tendencia %>% filter(evento != ""),
aes(
x = año, # Punto inicial x
y = valor - 5, # Punto inicial y
xend = año, # Punto final x
yend = valor + 5 # Punto final y
),
arrow = arrow(length = unit(0.2, "cm")),
color = "gray40"
) +
# Añadimos textos explicativos
geom_text(
data = datos_tendencia %>% filter(evento != ""),
aes(label = evento,
y = valor + 7), # Movemos la posición y dentro del aes
size = 4
) +
# Personalizamos el diseño
scale_y_continuous(breaks = seq(40, 100, 10)) +
labs(
title = "Evolución Temporal con Anotaciones",
subtitle = "Identificando puntos clave y eventos",
x = "Año",
y = "Valor"
) +
theme_minimal() + # Usamos theme_minimal() en lugar de tema_personalizado
theme(
plot.title = element_text(face = "bold", size = 16),
plot.subtitle = element_text(size = 12, color = "gray40"),
axis.title = element_text(face = "bold"),
panel.grid.minor = element_blank()
)Warning: Using `size` aesthetic for lines was deprecated in ggplot2 3.4.0.
ℹ Please use `linewidth` instead.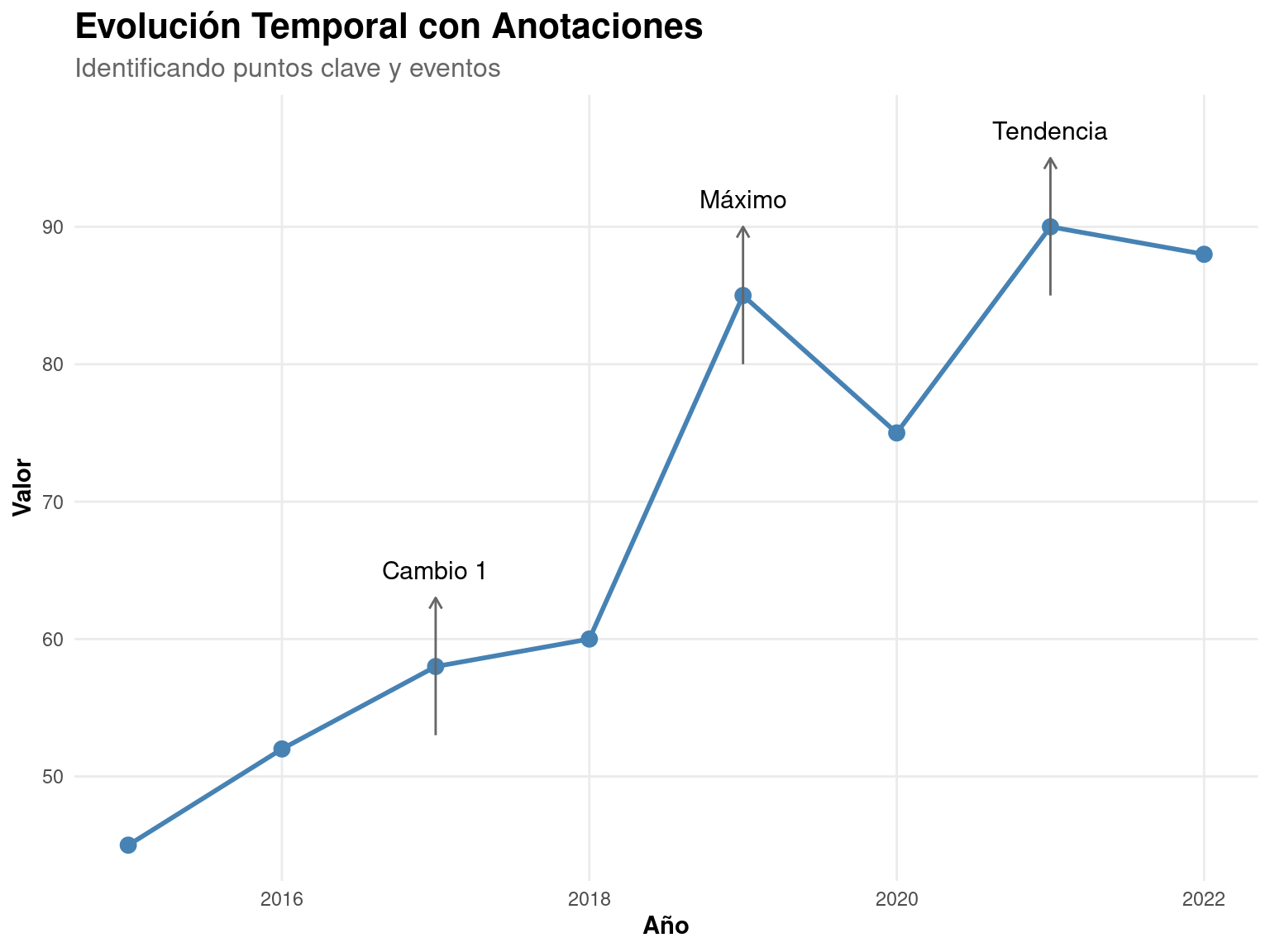
4.3 Interactividad Avanzada con plotly
La interactividad puede añadir una capa adicional de información a nuestros gráficos:
# Creamos datos más complejos
datos_interactivos <- tibble(
categoria = rep(c("A", "B", "C"), each = 4),
subcategoria = rep(c("Q1", "Q2", "Q3", "Q4"), 3),
valor = sample(50:100, 12),
tendencia = sample(c("↑", "↓", "→"), 12, replace = TRUE)
) %>%
mutate(
tooltip_texto = sprintf(
"Categoría: %s<br>Período: %s<br>Valor: %d<br>Tendencia: %s",
categoria, subcategoria, valor, tendencia
)
)
# Creamos gráfico base con ggplot2
p <- ggplot(datos_interactivos,
aes(x = subcategoria,
y = valor,
fill = categoria,
text = tooltip_texto)) +
geom_col(position = "dodge") +
scale_fill_viridis_d() +
labs(
title = "Evolución por Categoría y Período",
x = "Período",
y = "Valor",
fill = "Categoría"
) +
tema_personalizado
# Convertimos a interactivo
ggplotly(p, tooltip = "text") %>%
layout(
hoverlabel = list(bgcolor = "white"),
showlegend = TRUE
)Gráfico interactivo con tooltips personalizados
4.4 Gestión de Espacio y Composición
La gestión eficiente del espacio es crucial en visualizaciones complejas:
# Creamos varios gráficos relacionados
p1 <- ggplot(datos_interactivos,
aes(x = subcategoria, y = valor)) +
geom_col(aes(fill = categoria)) +
scale_fill_viridis_d() +
labs(title = "Vista General") +
tema_personalizado
p2 <- ggplot(datos_interactivos,
aes(x = categoria, y = valor)) +
geom_boxplot(aes(fill = categoria)) +
scale_fill_viridis_d() +
labs(title = "Distribución por Categoría") +
tema_personalizado
p3 <- ggplot(datos_interactivos,
aes(x = subcategoria, y = valor, color = categoria)) +
geom_line(aes(group = categoria)) +
geom_point() +
scale_color_viridis_d() +
labs(title = "Tendencias Temporales") +
tema_personalizado
# Componemos el layout
(p1 + p2) / p3 +
plot_annotation(
title = "Análisis Multidimensional de Datos Categóricos",
subtitle = "Diferentes perspectivas de los mismos datos",
caption = "Fuente: Datos de ejemplo",
tag_levels = "A"
) &
theme(plot.title = element_text(size = 20))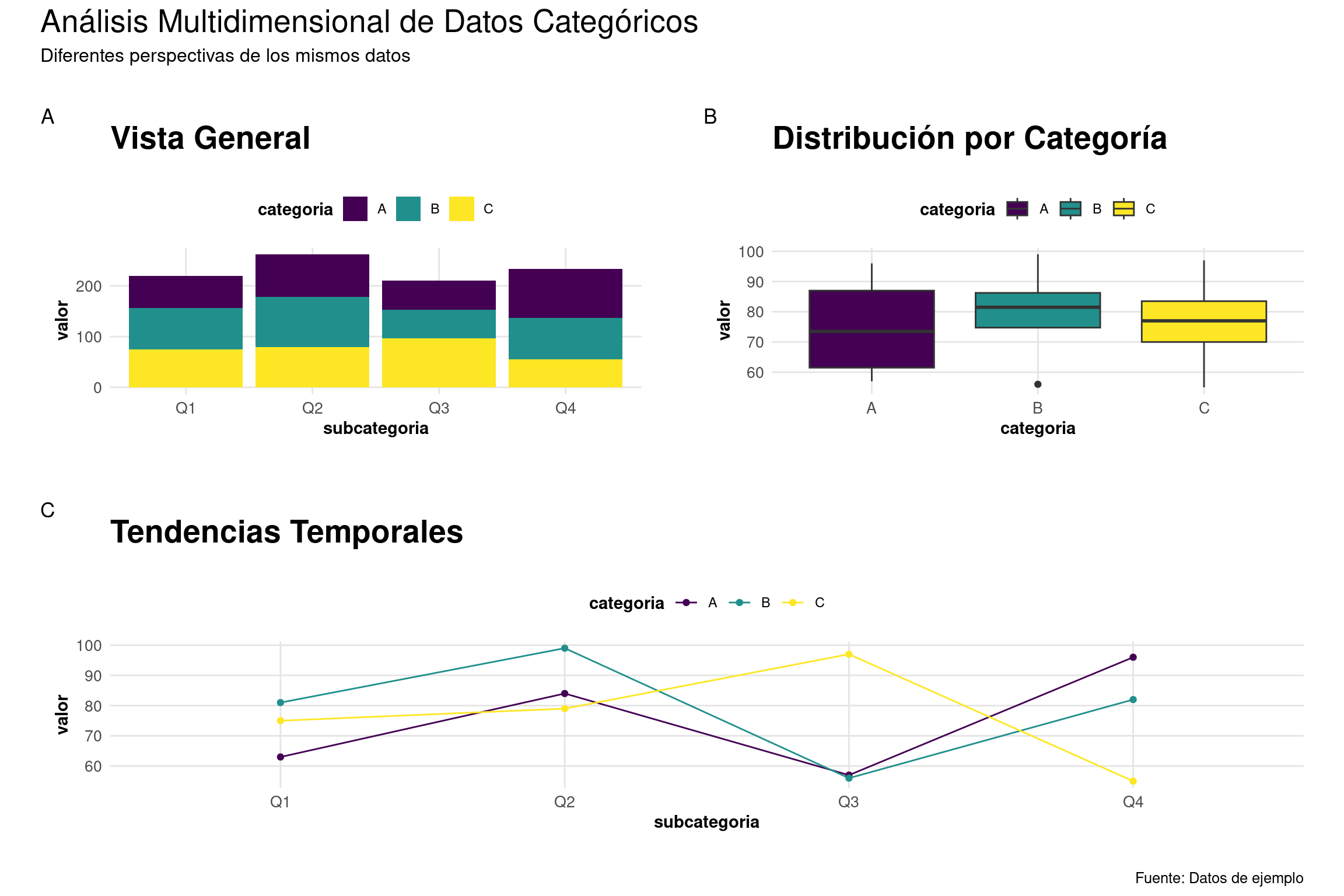
Elementos clave de la composición:
- Jerarquía visual clara
- Uso eficiente del espacio
- Consistencia en el diseño
- Balance entre información y claridad
5. Consideraciones de Accesibilidad y Mejores Prácticas
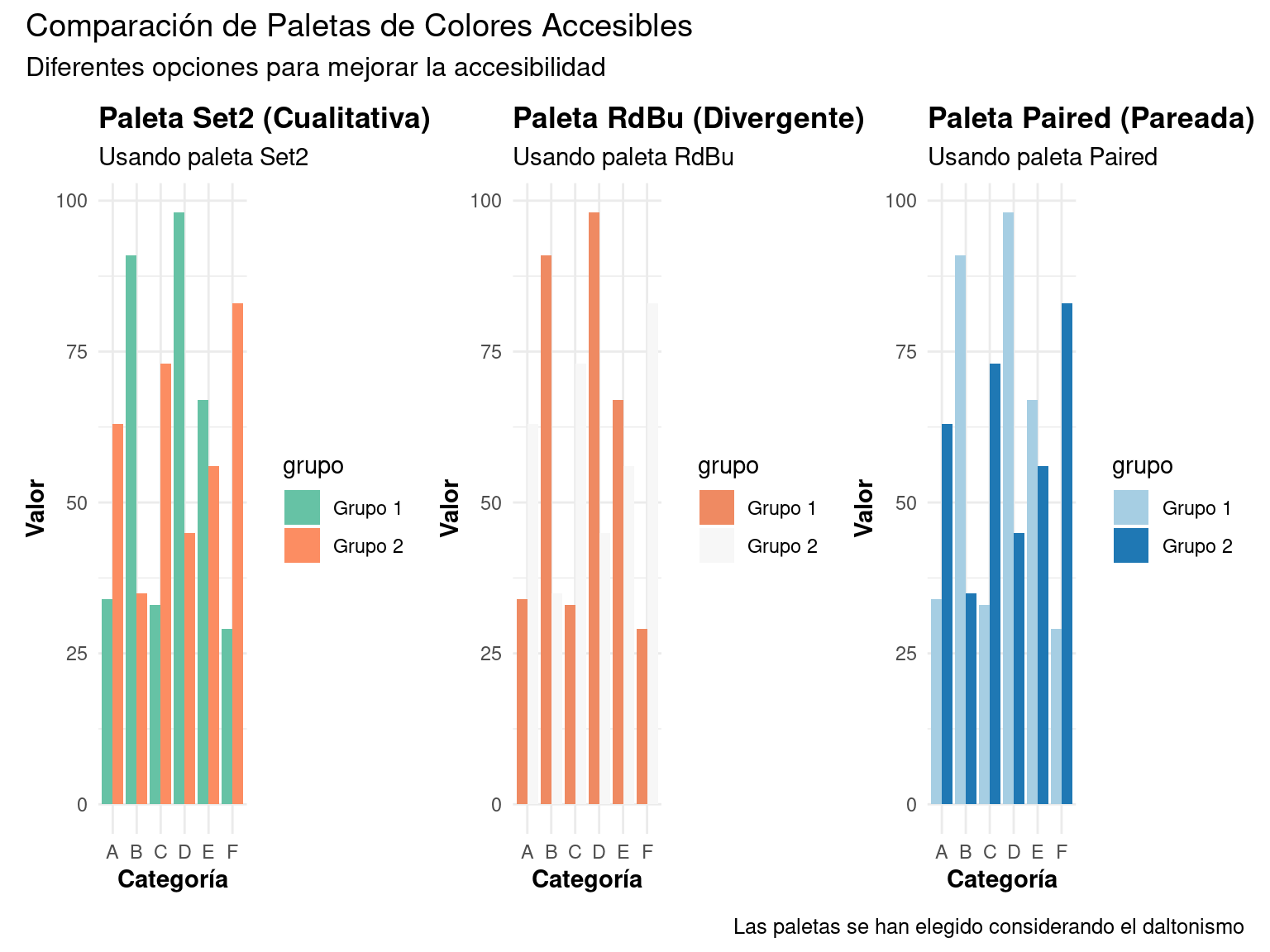
5.1 Diseño Accesible con Paletas de Colores
La accesibilidad en visualización de datos es fundamental. Aprenderemos a crear gráficos que sean accesibles para personas con daltonismo:
# Creamos datos de ejemplo
datos_accesibles <- tibble(
categoria = rep(LETTERS[1:6], each = 2),
grupo = rep(c("Grupo 1", "Grupo 2"), 6),
valor = sample(20:100, 12)
)
# Función para crear gráficos con diferentes paletas
crear_grafico_accesible <- function(datos, palette_name, titulo) {
ggplot(datos, aes(x = categoria, y = valor, fill = grupo)) +
geom_bar(stat = "identity", position = "dodge") +
scale_fill_brewer(palette = palette_name) + # Usamos paletas ColorBrewer
labs(
title = titulo,
subtitle = paste("Usando paleta", palette_name),
x = "Categoría",
y = "Valor"
) +
theme_minimal() +
theme(
plot.title = element_text(face = "bold"),
axis.title = element_text(face = "bold")
)
}
# Creamos múltiples versiones con diferentes paletas
p1 <- crear_grafico_accesible(datos_accesibles, "Set2", "Paleta Set2 (Cualitativa)")
p2 <- crear_grafico_accesible(datos_accesibles, "RdBu", "Paleta RdBu (Divergente)")
p3 <- crear_grafico_accesible(datos_accesibles, "Paired", "Paleta Paired (Pareada)")
# Mostramos los gráficos
(p1 | p2 | p3) +
plot_annotation(
title = "Comparación de Paletas de Colores Accesibles",
subtitle = "Diferentes opciones para mejorar la accesibilidad",
caption = "Las paletas se han elegido considerando el daltonismo"
)
# También podemos usar viridis que es accesible por defecto
p4 <- ggplot(datos_accesibles,
aes(x = categoria, y = valor, fill = grupo)) +
geom_bar(stat = "identity", position = "dodge") +
scale_fill_viridis_d() +
labs(
title = "Usando Paleta Viridis",
subtitle = "Óptima para accesibilidad y escala de grises",
x = "Categoría",
y = "Valor"
) +
theme_minimal()
# Mostramos el gráfico con viridis
p4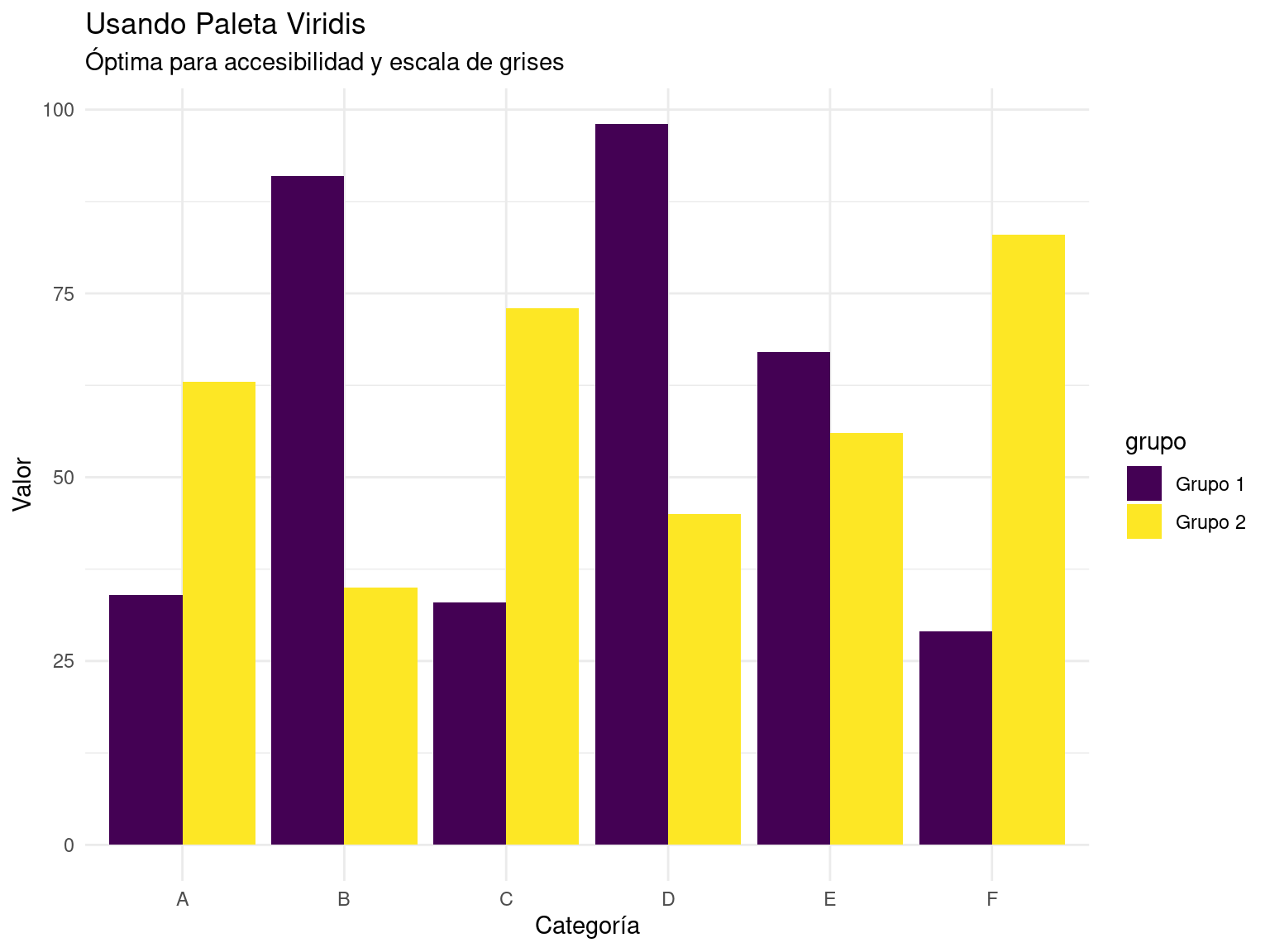
5.2 Uso de Formas y Patrones
No solo dependemos del color para diferenciar categorías:
# Creamos datos de ejemplo
datos_patrones <- tibble(
x = rep(1:5, 3),
y = rnorm(15, mean = 10, sd = 2),
grupo = rep(c("A", "B", "C"), each = 5)
)
# Gráfico con formas diferentes
p1 <- ggplot(datos_patrones,
aes(x = x, y = y, shape = grupo, color = grupo)) +
geom_point(size = 4) +
geom_line(aes(linetype = grupo)) +
scale_shape_manual(values = c(16, 17, 15)) +
scale_linetype_manual(values = c("solid", "dashed", "dotted")) +
labs(
title = "Uso de Formas y Líneas",
subtitle = "Diferenciación mediante múltiples elementos visuales",
x = "Posición",
y = "Valor"
) +
theme_minimal()
# Gráfico con patrones de relleno
#install.packages("ggpattern")
library(ggpattern)
datos_barras <- tibble(
categoria = LETTERS[1:4],
valor = sample(20:100, 4),
patron = letters[1:4]
)
p2 <- ggplot(datos_barras,
aes(x = categoria, y = valor, fill = categoria, pattern = patron)) +
geom_bar_pattern(
stat = "identity",
pattern_fill = "black",
pattern_angle = 45,
pattern_density = 0.1,
pattern_spacing = 0.025,
position = "identity"
) +
scale_pattern_manual(values = c("stripe", "circle", "crosshatch", "dot")) +
labs(
title = "Uso de Patrones de Relleno",
subtitle = "Diferenciación mediante texturas",
x = "Categoría",
y = "Valor"
) +
theme_minimal()
# Mostramos los gráficos
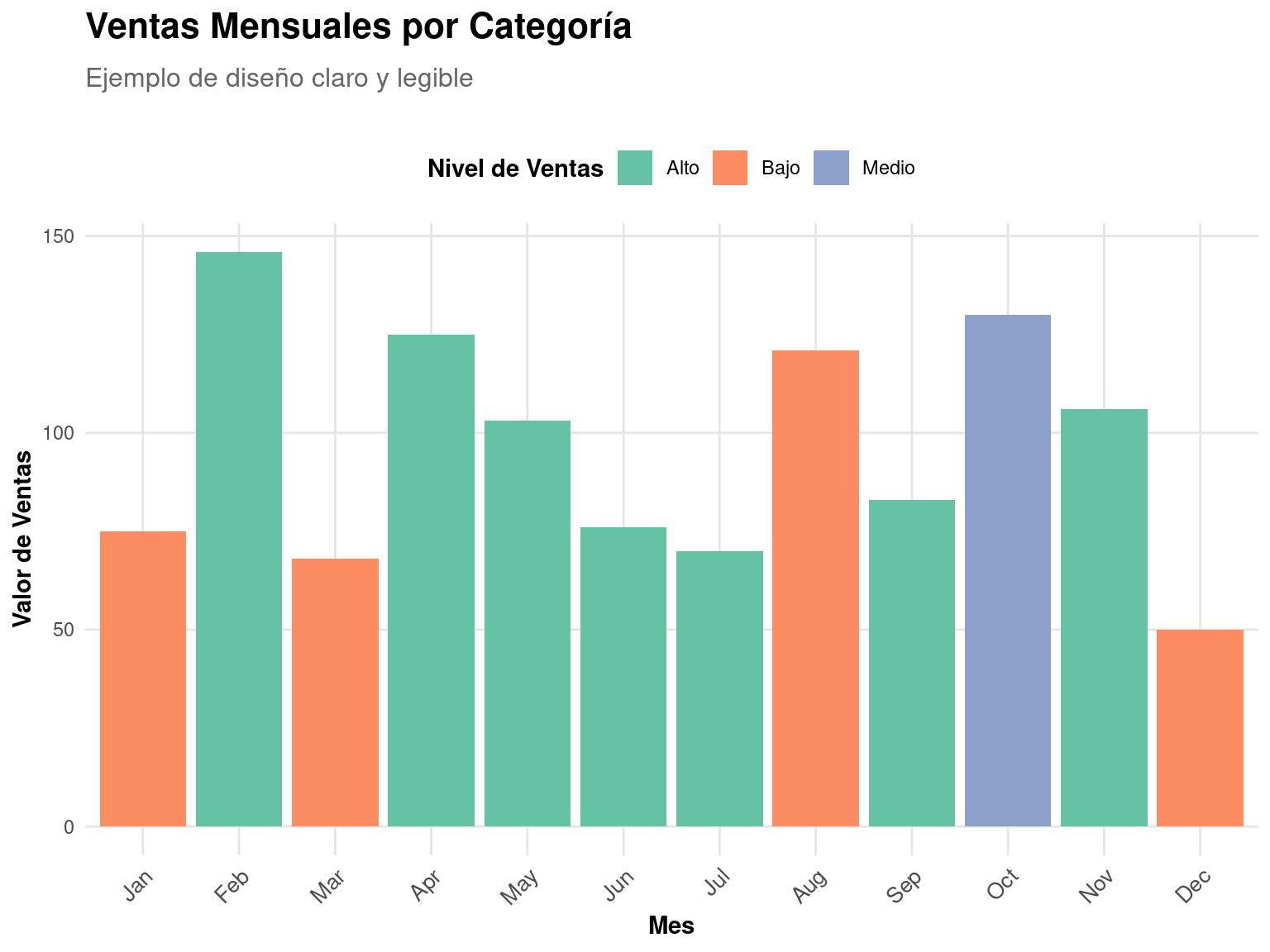
p1 / p25.3 Diseño Claro y Legible
La claridad en la presentación es crucial:
# Creamos datos de ejemplo
datos_clarity <- tibble(
mes = factor(month.abb[1:12], levels = month.abb[1:12]),
valor = sample(50:150, 12),
categoria = sample(c("Alto", "Medio", "Bajo"), 12, replace = TRUE)
)
# Gráfico con diseño claro
ggplot(datos_clarity,
aes(x = mes, y = valor, fill = categoria)) +
geom_col() +
scale_fill_brewer(palette = "Set2") +
labs(
title = "Ventas Mensuales por Categoría",
subtitle = "Ejemplo de diseño claro y legible",
x = "Mes",
y = "Valor de Ventas",
fill = "Nivel de Ventas"
) +
theme_minimal() +
theme(
# Títulos claros
plot.title = element_text(
size = 16,
face = "bold",
margin = margin(b = 10)
),
plot.subtitle = element_text(
size = 12,
color = "gray40",
margin = margin(b = 20)
),
# Ejes legibles
axis.text.x = element_text(
angle = 45,
hjust = 1,
size = 10
),
axis.title = element_text(face = "bold"),
# Leyenda clara
legend.position = "top",
legend.title = element_text(face = "bold"),
# Grilla sutil
panel.grid.minor = element_blank(),
panel.grid.major = element_line(color = "gray90")
)
5.4 Documentación y Reproducibilidad
Es importante documentar nuestro código y hacerlo reproducible:
# Creamos una función reutilizable para gráficos de barras
crear_grafico_barras <- function(datos,
var_x,
var_y,
var_fill = NULL,
titulo = "Gráfico de Barras",
subtitulo = NULL,
x_lab = var_x,
y_lab = var_y,
palette = "viridis") {
# Construimos la llamada aesthtics
if (is.null(var_fill)) {
aes_mapping <- aes_string(x = var_x, y = var_y)
} else {
aes_mapping <- aes_string(x = var_x, y = var_y, fill = var_fill)
}
# Creamos el gráfico base
p <- ggplot(datos, aes_mapping) +
geom_col(position = "dodge", alpha = 0.8) +
labs(
title = titulo,
subtitle = subtitulo,
x = x_lab,
y = y_lab
) +
theme_minimal() +
theme(
plot.title = element_text(face = "bold", size = 14),
axis.title = element_text(face = "bold"),
legend.position = "top"
)
# Añadimos la paleta de colores si es necesario
if (!is.null(var_fill)) {
if (palette == "viridis") {
p <- p + scale_fill_viridis_d()
} else {
p <- p + scale_fill_brewer(palette = palette)
}
}
return(p)
}
# Ejemplo de uso
datos_ejemplo <- tibble(
categoria = rep(LETTERS[1:4], each = 3),
subcategoria = rep(c("X", "Y", "Z"), 4),
valor = sample(20:100, 12)
)
# Creamos varios gráficos usando la función
p1 <- crear_grafico_barras(
datos_ejemplo,
"categoria",
"valor",
titulo = "Gráfico Simple"
)Warning: `aes_string()` was deprecated in ggplot2 3.0.0.
ℹ Please use tidy evaluation idioms with `aes()`.
ℹ See also `vignette("ggplot2-in-packages")` for more information.p2 <- crear_grafico_barras(
datos_ejemplo,
"categoria",
"valor",
"subcategoria",
titulo = "Gráfico con Grupos",
palette = "Set2"
)
# Mostramos los gráficos
p1 / p2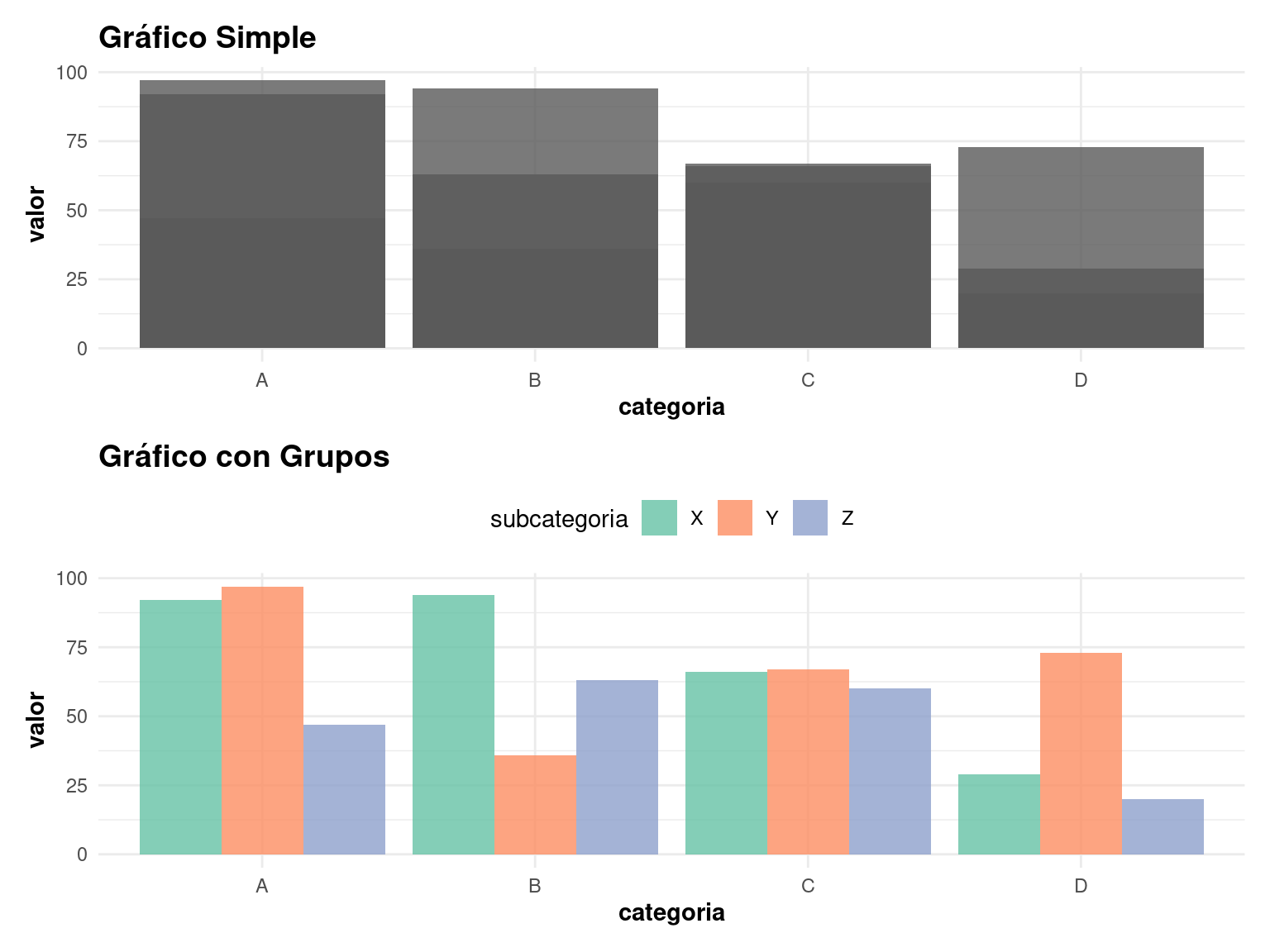
6. Casos Prácticos y Aplicaciones Avanzadas
6.1 Análisis de Encuestas
Veamos cómo visualizar datos típicos de encuestas con múltiples variables categóricas:
set.seed(123)
n_encuestados <- 1000
# Función para generar distribuciones diferentes por edad
generar_satisfaccion <- function(grupo_edad) {
case_when(
grupo_edad == "18-25" ~ sample(c("Muy Baja", "Baja", "Media", "Alta", "Muy Alta"),
1, prob = c(0.3, 0.3, 0.2, 0.1, 0.1)),
grupo_edad == "26-35" ~ sample(c("Muy Baja", "Baja", "Media", "Alta", "Muy Alta"),
1, prob = c(0.1, 0.2, 0.4, 0.2, 0.1)),
grupo_edad == "36-45" ~ sample(c("Muy Baja", "Baja", "Media", "Alta", "Muy Alta"),
1, prob = c(0.1, 0.1, 0.3, 0.3, 0.2)),
grupo_edad == "46-55" ~ sample(c("Muy Baja", "Baja", "Media", "Alta", "Muy Alta"),
1, prob = c(0.05, 0.15, 0.2, 0.4, 0.2)),
grupo_edad == "56+" ~ sample(c("Muy Baja", "Baja", "Media", "Alta", "Muy Alta"),
1, prob = c(0.05, 0.1, 0.15, 0.3, 0.4))
)
}
# Función para generar distribuciones educativas diferentes por género
generar_educacion <- function(genero) {
case_when(
genero == "Femenino" ~ sample(c("Básica", "Media", "Superior", "Postgrado"),
1, prob = c(0.1, 0.3, 0.4, 0.2)),
genero == "Masculino" ~ sample(c("Básica", "Media", "Superior", "Postgrado"),
1, prob = c(0.2, 0.35, 0.3, 0.15)),
genero == "Otro" ~ sample(c("Básica", "Media", "Superior", "Postgrado"),
1, prob = c(0.05, 0.15, 0.5, 0.3))
)
}
# Creamos los datos con patrones más marcados
datos_encuesta <- tibble(
edad_grupo = sample(c("18-25", "26-35", "36-45", "46-55", "56+"),
n_encuestados, replace = TRUE,
prob = c(0.25, 0.3, 0.2, 0.15, 0.1))
) %>%
mutate(
genero = sample(c("Femenino", "Masculino", "Otro"),
n_encuestados, replace = TRUE,
prob = c(0.45, 0.45, 0.1))
) %>%
rowwise() %>%
mutate(
satisfaccion = generar_satisfaccion(edad_grupo),
educacion = generar_educacion(genero)
) %>%
ungroup()
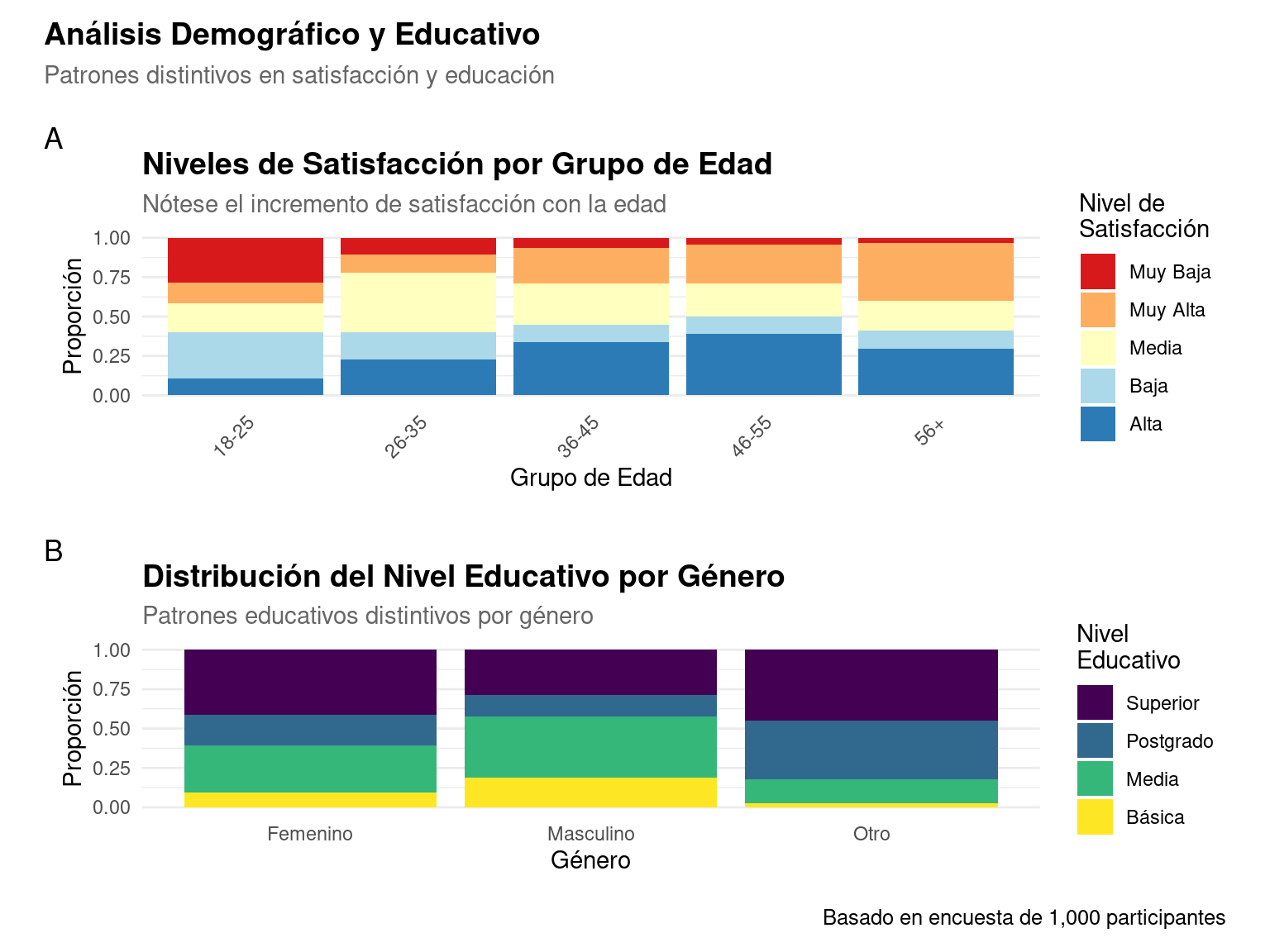
# 1. Gráfico de satisfacción por edad mejorado
p1 <- ggplot(datos_encuesta,
aes(x = edad_grupo, fill = fct_rev(satisfaccion))) + # Revertimos el orden para mejor visualización
geom_bar(position = "fill") +
scale_fill_brewer(palette = "RdYlBu") + # Cambiamos a una paleta más contrastante
labs(
title = "Niveles de Satisfacción por Grupo de Edad",
subtitle = "Nótese el incremento de satisfacción con la edad",
x = "Grupo de Edad",
y = "Proporción",
fill = "Nivel de\nSatisfacción"
) +
theme_minimal() +
theme(
axis.text.x = element_text(angle = 45, hjust = 1),
plot.title = element_text(face = "bold", size = 12),
plot.subtitle = element_text(size = 10, color = "gray40"),
legend.position = "right",
panel.grid.major.x = element_blank()
)
# 2. Gráfico de distribución educativa por género mejorado
p2 <- ggplot(datos_encuesta,
aes(x = genero, fill = fct_rev(educacion))) + # Revertimos el orden
geom_bar(position = "fill") +
scale_fill_viridis_d(option = "D") + # Usamos viridis para mejor contraste
labs(
title = "Distribución del Nivel Educativo por Género",
subtitle = "Patrones educativos distintivos por género",
x = "Género",
y = "Proporción",
fill = "Nivel\nEducativo"
) +
theme_minimal() +
theme(
axis.text.x = element_text(angle = 0),
plot.title = element_text(face = "bold", size = 12),
plot.subtitle = element_text(size = 10, color = "gray40"),
legend.position = "right",
panel.grid.major.x = element_blank()
)
# Combinamos los gráficos
p1 / p2 +
plot_annotation(
title = "Análisis Demográfico y Educativo",
subtitle = "Patrones distintivos en satisfacción y educación",
caption = "Basado en encuesta de 1,000 participantes",
tag_levels = "A"
) &
theme(
plot.title = element_text(size = 14, face = "bold"),
plot.subtitle = element_text(size = 11, color = "gray40"),
plot.margin = margin(10, 10, 10, 10)
)
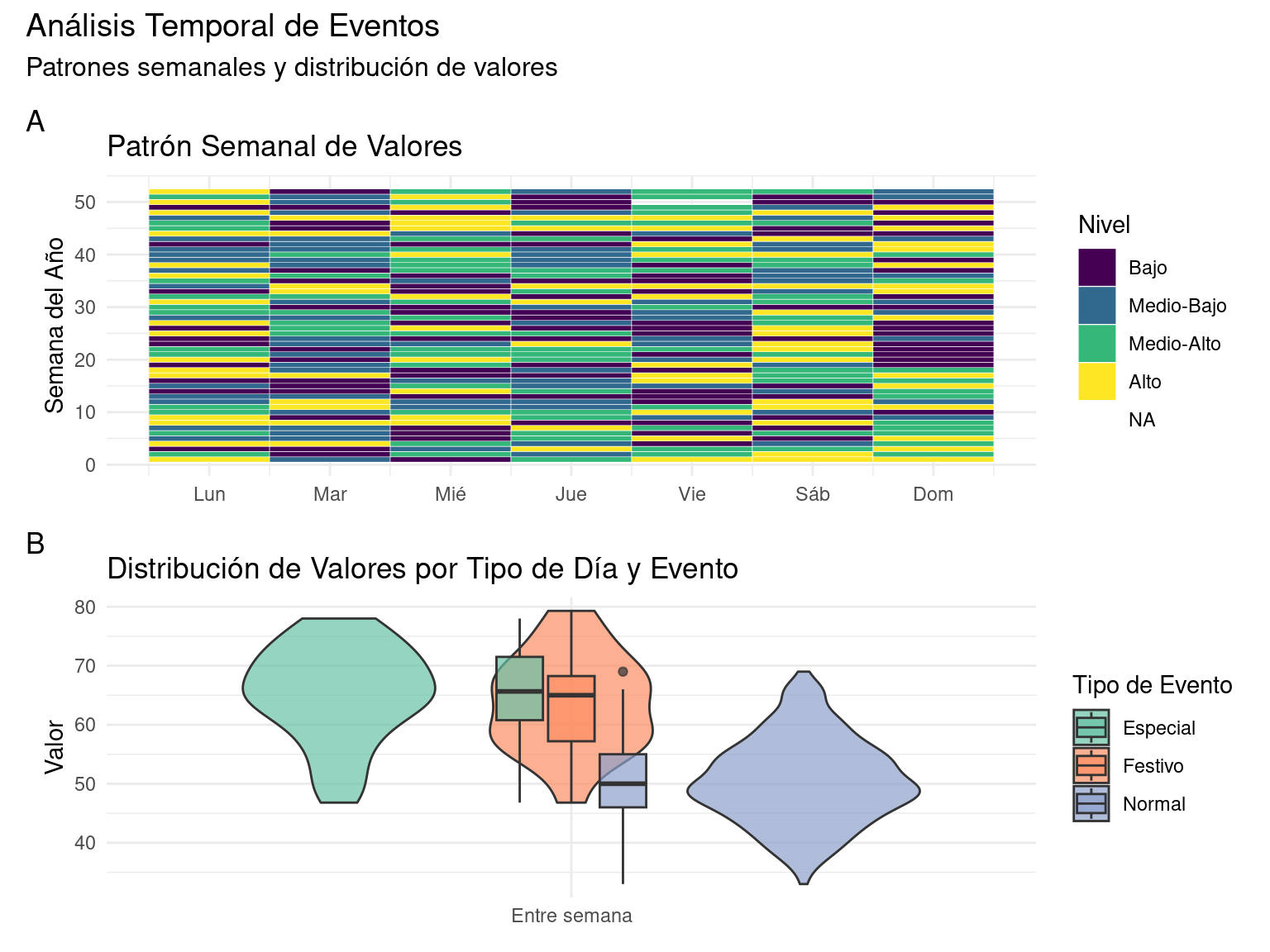
6.2 Análisis de Series Temporales Categóricas
Veamos cómo visualizar datos temporales con componentes categóricos:
# Creamos datos de series temporales
fechas <- seq.Date(from = as.Date("2022-01-01"),
to = as.Date("2022-12-31"),
by = "day")
datos_tiempo <- tibble(
fecha = fechas,
mes = format(fecha, "%B"),
dia_semana = weekdays(fecha),
tipo_dia = ifelse(dia_semana %in% c("Saturday", "Sunday"),
"Fin de semana", "Entre semana"),
eventos = sample(c("Normal", "Especial", "Festivo"),
length(fechas),
prob = c(0.8, 0.15, 0.05),
replace = TRUE),
valor = rpois(length(fechas), lambda = 50) *
(1 + 0.5 * (tipo_dia == "Fin de semana")) *
(1 + 0.3 * (eventos != "Normal"))
)
# 1. Gráfico de calendario
# Agregamos semana y día para el calendario
datos_tiempo <- datos_tiempo %>%
mutate(
semana = as.numeric(format(fecha, "%V")),
dia = as.numeric(format(fecha, "%u")),
valor_cat = cut(valor,
breaks = quantile(valor, probs = seq(0, 1, 0.25)),
labels = c("Bajo", "Medio-Bajo", "Medio-Alto", "Alto"))
)
# Creamos el gráfico de calendario
p1 <- ggplot(datos_tiempo,
aes(x = dia, y = semana, fill = valor_cat)) +
geom_tile(color = "white") +
scale_fill_viridis_d() +
scale_x_continuous(
breaks = 1:7,
labels = c("Lun", "Mar", "Mié", "Jue", "Vie", "Sáb", "Dom")
) +
labs(
title = "Patrón Semanal de Valores",
x = NULL,
y = "Semana del Año",
fill = "Nivel"
) +
theme_minimal()
# 2. Gráfico de violín por tipo de día y evento
p2 <- ggplot(datos_tiempo,
aes(x = tipo_dia, y = valor, fill = eventos)) +
geom_violin(alpha = 0.7) +
geom_boxplot(width = 0.2, alpha = 0.7) +
scale_fill_brewer(palette = "Set2") +
labs(
title = "Distribución de Valores por Tipo de Día y Evento",
x = NULL,
y = "Valor",
fill = "Tipo de Evento"
) +
theme_minimal()
# Combinamos los gráficos
p1 / p2 +
plot_annotation(
title = "Análisis Temporal de Eventos",
subtitle = "Patrones semanales y distribución de valores",
tag_levels = "A"
)
6.3 Visualización de Redes Sociales
Veamos cómo visualizar datos de redes sociales con características categóricas:
# Creamos datos de red social simulados
set.seed(123)
n_nodos <- 30
# Datos de nodos
nodos <- tibble(
id = 1:n_nodos,
tipo = sample(c("Influencer", "Regular", "Nuevo"), n_nodos,
prob = c(0.2, 0.6, 0.2), replace = TRUE),
actividad = sample(c("Alta", "Media", "Baja"), n_nodos,
prob = c(0.3, 0.5, 0.2), replace = TRUE),
tamaño = case_when(
tipo == "Influencer" ~ runif(n_nodos, 20, 30),
tipo == "Regular" ~ runif(n_nodos, 10, 20),
TRUE ~ runif(n_nodos, 5, 10)
)
)
# Crear conexiones
enlaces <- tibble(
from = sample(1:n_nodos, 50, replace = TRUE),
to = sample(1:n_nodos, 50, replace = TRUE)
) %>%
filter(from != to) %>%
distinct()
# Crear grafo con tidygraph
grafo <- tbl_graph(nodes = nodos, edges = enlaces)
# Visualizar con ggraph
ggraph(grafo, layout = "fr") +
geom_edge_link(alpha = 0.2) +
geom_node_point(aes(size = tamaño,
color = tipo,
shape = actividad),
alpha = 0.8) +
scale_color_brewer(palette = "Set2") +
scale_size_continuous(range = c(3, 8)) +
labs(
title = "Red Social de Usuarios",
subtitle = "Visualización de conexiones y características",
color = "Tipo de Usuario",
size = "Tamaño de Red",
shape = "Nivel de Actividad"
) +
theme_graph()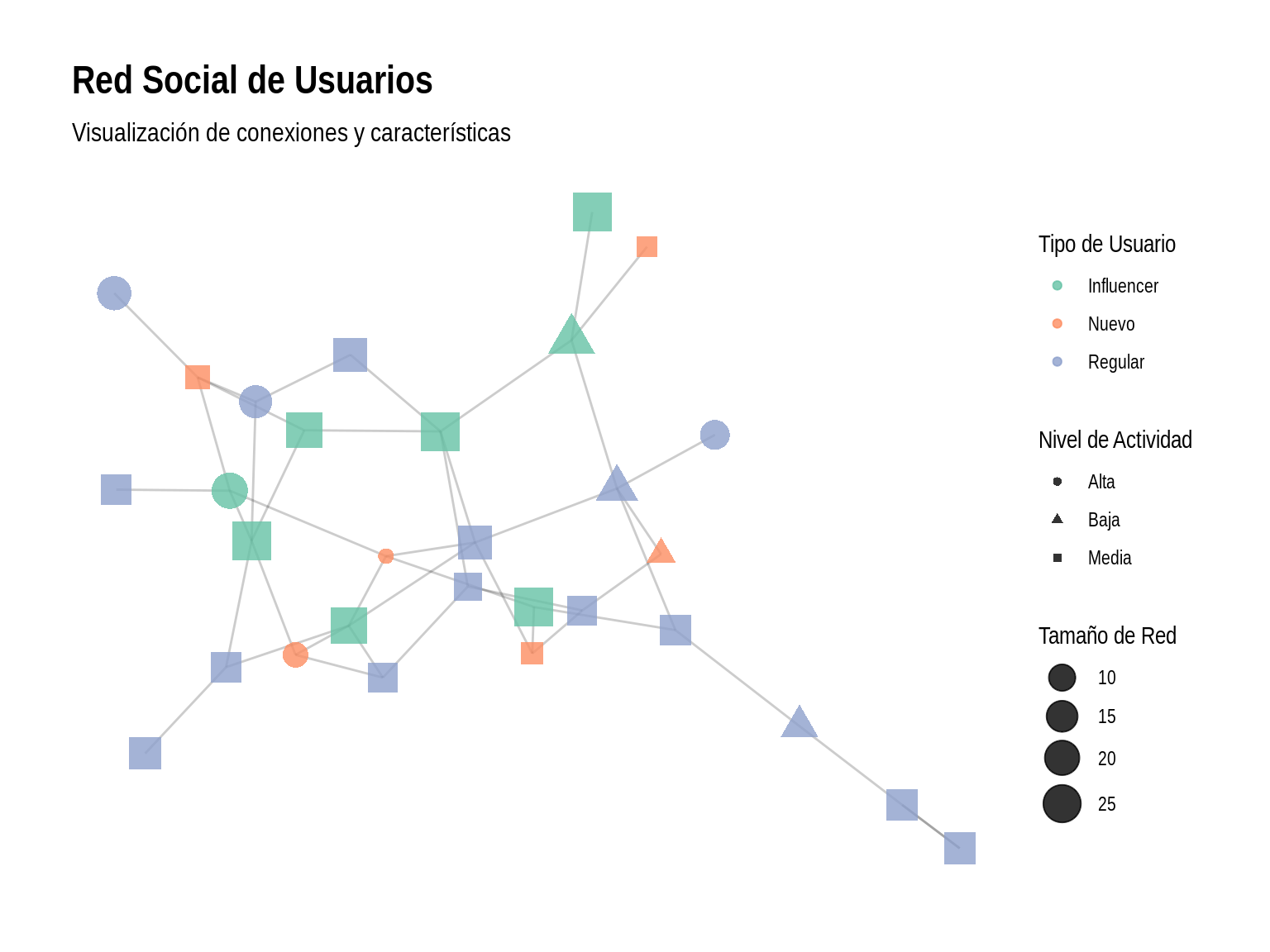
7. Recomendaciones Finales y Mejores Prácticas
7.1 Elección del Tipo de Visualización
- Para comparaciones entre categorías:
- Gráficos de barras (pocas categorías)
- Lollipop charts (muchas categorías)
- Treemaps (jerarquías)
- Para relaciones entre variables categóricas:
- Gráficos de mosaico
- Heatmaps
- Diagramas de Sankey
- Para datos temporales categóricos:
- Gráficos de calendario
- Gráficos de líneas segmentados
- Streamgraphs
7.2 Consideraciones de Diseño
- Accesibilidad:
- Usar paletas de colores amigables para daltónicos
- Incluir elementos redundantes (forma + color)
- Mantener alto contraste
- Claridad:
- Limitar el número de categorías mostradas
- Usar etiquetas claras y legibles
- Incluir títulos y subtítulos informativos
- Interactividad:
- Añadir cuando aporte valor
- Mantener la simplicidad
- Incluir tooltips informativos
7.3 Recursos Adicionales
- Libros Recomendados:
- “ggplot2: Elegant Graphics for Data Analysis” por Hadley Wickham
- “Fundamentals of Data Visualization” por Claus O. Wilke
- “R Graphics Cookbook” por Winston Chang
- Sitios Web:
- Paquetes Útiles:
- ggplot2: base de visualización
- ggthemes: temas adicionales
- plotly: interactividad
- ggridges: gráficos de ridgeline
- ggalluvial: diagramas de Sankey