pacman::p_load(
ergm,
ergm.ego,
car,
egor,
tidyverse,
tibble,
texreg,
purrr,
tidyr,
prioritizr,
questionr,
Rglpk)libraries
data
load("/home/rober/Documents/rcantillan.github.io/dat/ELSOC/ELSOC_W02_v3.00_R.RData")
load("/home/rober/Documents/rcantillan.github.io/dat/ELSOC/ELSOC_W04_v2.01_R.RData")
load("/home/rober/Documents/rcantillan.github.io/dat/ELSOC/ELSOC_W01_v4.01_R.RData")Procesamiento
Renombrar ID
a<-elsoc_2017 %>% dplyr::rename(.egoID = idencuesta)Crear data frame alteris para 2017=a
Creamos subset con data de cada uno de los alteris mencionados, manteniendo el ID de cada ego en el cual están anidados. Las columnas de cada uno de los subset deben tener los mismos nombres.
columnas <- c("sexo", "edad", "educ", "relig", "ideol", "barrio", "relacion")
num_alters <- 5
alter_list <- list()
for (i in 1:num_alters) {
alter_cols <- paste0("r13_", columnas, "_", sprintf("%02d", i))
alter <- a %>%
dplyr::select(.egoID, all_of(alter_cols)) %>%
rename_with(~ columnas, alter_cols) %>%
mutate(n = i)
alter_list[[i]] <- alter
}
alteris <- bind_rows(alter_list)
alteris<-arrange(alteris, .egoID)Crear vector alter id
En el siguiente chunk creamos un vector identificador para cada uno de los alteris presentes en la data “alteris”. Lo identificamos como objeto tibble y eliminamos el vector “n”.
alteris <- rowid_to_column(alteris, var = ".alterID")
alteris <- as_tibble(alteris)
alteris$n <- NULLRecod alteris
Recodificamos los valores de los atributos de los alteris.
# NA
alteris[alteris=="-999"]<-NA
alteris[alteris=="-888"]<-NA
# Educación
#edulab<-c('ltsecondary', 'secondary', 'technicaled', 'collegeed')
alteris$educ <-factor(Recode(alteris$educ ,"1=1;2:3=2;4=3;5=4"))
table(alteris$educ)
1 2 3 4
1362 3543 1042 1719 # Religión
#relilab<-c('catholic','evangelical','other','none')
alteris$relig<-factor(Recode(alteris$relig,"1=1;2=2;3:4=4;5=3"))
table(alteris$relig)
1 2 3 4
4907 1407 373 1379 # Ideología
#ideolab<-c('rightwinger','centerright','center','centerleft','leftwinger','none')
alteris$ideol<-factor(Recode(alteris$ideol,"1=1;2=2;3=3;4=4;5=5;6=6"))
table(alteris$ideol)
1 2 3 4 5 6
786 191 382 303 759 4644 # Edad
alteris$edad<-as.numeric(alteris$edad)
#alteris$edad <-factor(Recode(alteris$edad ,"0:18=1;19:29=2;30:40=3;41:51=4;52:62=5;63:100=6"))
# Sexo
#sexolab<-c('male','female')
alteris$sexo <-factor(Recode(alteris$sexo ,"1=1;2=2"))
table(alteris$sexo)
1 2
3388 4678 # Relación
alteris<-alteris%>%
dplyr::mutate(rel=case_when(relacion%in%1:3~"fam",
relacion%in%4:5~"nofam"))
table(alteris$relacion)
1 2 3 4 5
951 1181 2519 2577 838 # Barrio
alteris$barrio<-factor(Recode(alteris$barrio,"1=1;2=2"))
table(alteris$barrio)
1 2
4271 3788 #alteris<-na.omit(alteris)Borrar alteris con 5 parámetros con NA
# Función para borrar casos con un número determinado de NA's.
#delete.na <- function(DF, n=0) {
# DF[rowSums(is.na(DF)) <= n,]
#}
#
#alteris<-delete.na(alteris, 4) #borro los casos que tienen más de 4 NA. Data Frame Ego’s
Creamos un subset con la data de ego equivalente a la data de los alteris. Las nombramos de la misma manera.
egos <-a %>%
dplyr::select(.egoID,
sexo=m0_sexo,
edad=m0_edad,
educ=m01,
relig=m38,
ideol=c15,
ponderador02,
estrato,
segmento)
egos <- as_tibble(egos)Recod data Ego’s
Recodificamos las variables de la data de ego siguiendo el patrón de la data de alteris.
# NA
egos[egos=="-999"]<-NA
egos[egos=="-888"]<-NA
# Educación
egos$educ <-factor(Recode(egos$educ,"1:3=1;4:5=2;6:7=3;8:10=4"))
table(egos$educ)
1 2 3 4
597 1045 402 429 # Religión
egos$relig<-factor(Recode(egos$relig,"1=1;2=2;3:6=3;7:9=4"))
table(egos$relig)
1 2 3 4
1383 499 276 308 # Ideología
#ideolab2<-c('leftwinger','centerleft','center','centerright','rightwinger','none')
egos$ideol<-factor(Recode(egos$ideol,"0:2=5;3:4=4;5=3;6:7=2;8:10=1;11:12=6"))
table(egos$ideol)
1 2 3 4 5 6
252 149 470 209 282 1080 # Edad
egos$edad<-as.numeric(egos$edad)
#egos$edad <-factor(Recode(egos$edad,"18=1;19:29=2;30:40=3;41:51=4;52:62=5;63:100=6"))
# Sexo
egos$sexo <-factor(Recode(egos$sexo,"1=1;2=2"))
table(egos$sexo)
1 2
951 1522 # Barrio
egos$barrio <- matrix(rbinom(2473*5,1,0.6),2473,1) # Criterio minimalistaWarning in matrix(rbinom(2473 * 5, 1, 0.6), 2473, 1): data length differs from
size of matrix: [12365 != 2473 x 1]egos$barrio<-factor(Recode(egos$barrio,"1=1;0=2"))
table(egos$barrio)
1 2
1437 1036 Crear objeto Egor (requerido para trabajar con función ergm.ego)
# definir diseño complejo
elsoc_ego <- egor(alters = alteris,
egos = egos,
alter_design = list(max = 5),
ID.vars = list(
ego = ".egoID",
alter = ".alterID")) %>% as.egor()
ego_design(elsoc_ego) <- list(weight = "ponderador02",
strata = "estrato",
cluster="segmento")
# eliminar atributos de diseño
elsoc_ego[["ego"]][["variables"]][["ponderador02"]]<-NULL
elsoc_ego[["ego"]][["variables"]][["estrato"]]<-NULL
elsoc_ego[["ego"]][["variables"]][["segmento"]]<-NULL
# drop NA
variables <- c("sexo", "educ", "relig", "ideol", "barrio")
for (variable in variables) {
elsoc_ego[["ego"]] <- elsoc_ego[["ego"]] %>% drop_na({{ variable }})
elsoc_ego[["alter"]] <- elsoc_ego[["alter"]] %>% drop_na({{ variable }})
}
as_tibble(elsoc_ego$alter)# A tibble: 6,849 × 10
.altID .egoID sexo edad educ relig ideol barrio relacion rel
<chr> <chr> <fct> <dbl> <fct> <fct> <fct> <fct> <dbl> <chr>
1 1 1101011 1 77 2 1 5 1 1 fam
2 6 1101012 1 60 2 1 6 1 1 fam
3 11 1101013 2 54 1 1 6 1 3 fam
4 12 1101013 2 33 2 1 6 1 3 fam
5 16 1101021 1 55 2 1 6 1 4 nofam
6 21 1101022 2 44 4 4 6 1 2 fam
7 26 1101023 1 40 2 1 6 1 3 fam
8 31 1101032 2 31 4 1 6 1 2 fam
9 32 1101032 1 57 2 1 5 1 1 fam
10 36 1101033 1 37 2 1 2 1 1 fam
# ℹ 6,839 more rowsDegree distribution
Educación
degreedist(elsoc_ego, by="educ", prob=T, plot = T, weight=TRUE)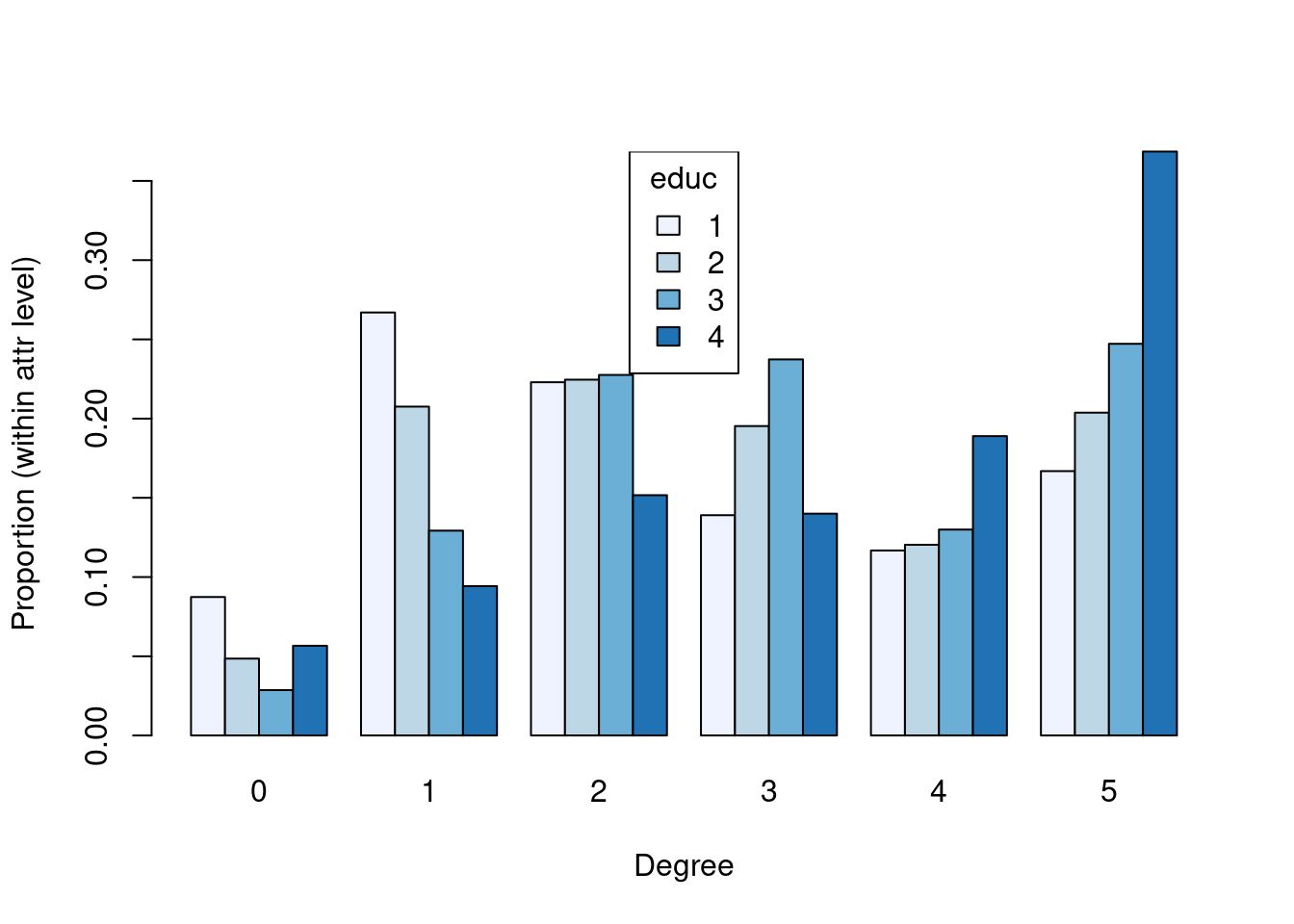
Sexo
degreedist(elsoc_ego, by="sexo", prob=T, plot = T, weight=TRUE)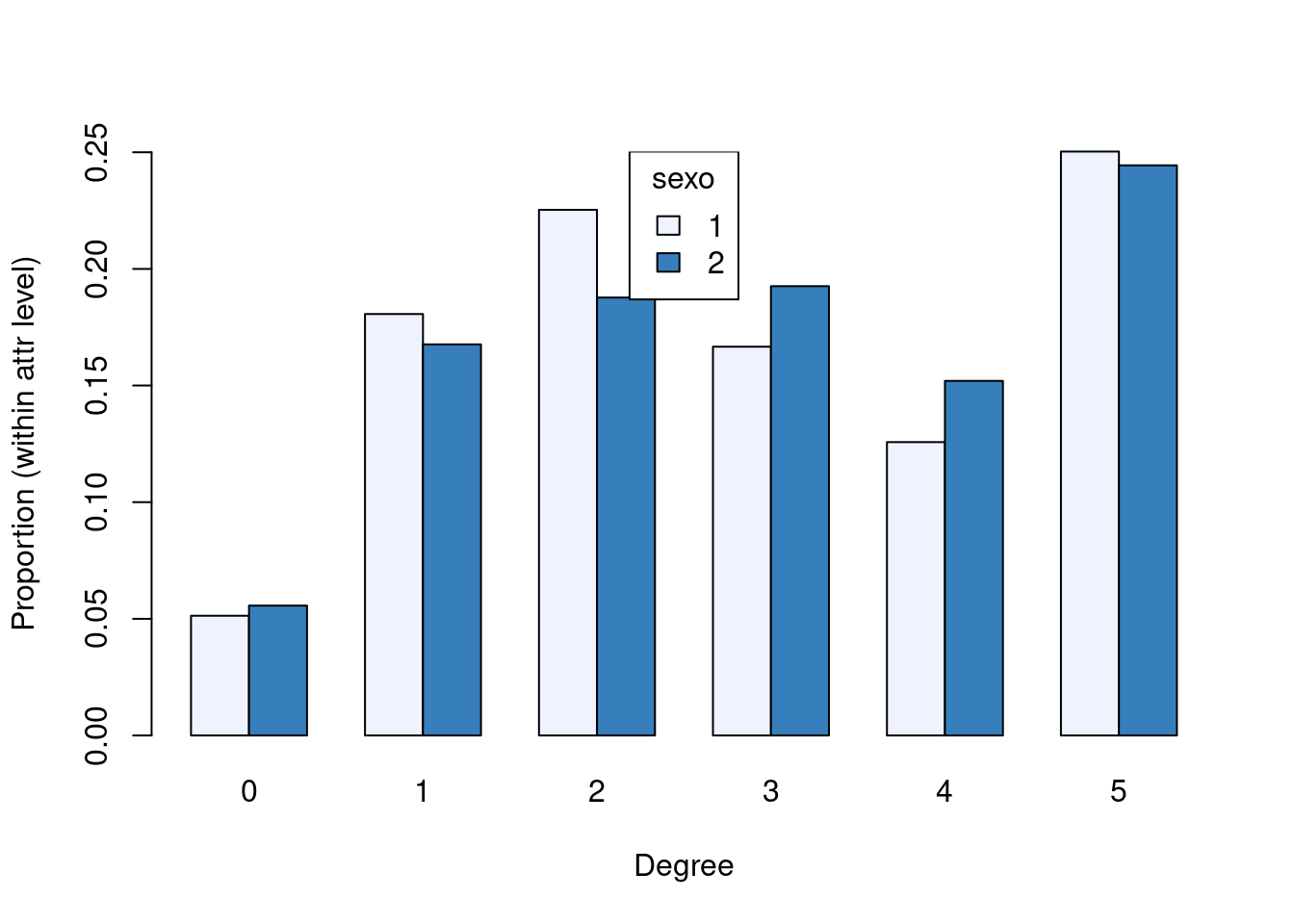
Modelos
nodefactor = controla el grado de los diferentes grupos (ajustando las estimaciones de homofilia por el hecho de que algunos grupos, por ejemplo, los hombres, tienen más vínculos que otros grupos, como las mujeres).
El paquete “ergm” proporciona no sólo estadísticas resumidas sino también valores-p. Sin embargo, como indica Kolaczyk y Csárdi (2020), la justificación teórica para las distribuciones asintóticas chi-cuadrado y F utilizadas por ergm para calcular estos valores no se ha establecido hasta la fecha. Por lo tanto, puede ser pertinente interpretar estos valores de manera informal, como estadísticas resumidas adicionales.
## Set # replicates
reps = 1
## Set ppop size and construction
ppop = 15000
ppopwt = 'round' # Round gives consistent netsize/composition
constraint.formula <- (~ bd(maxout = 5)) # constraint por grado máximo para cada ego. print(names(elsoc_ego$ego))[1] "cluster" "strata" "has.strata" "prob" "allprob"
[6] "call" "variables" "fpc" "pps" print(names(elsoc_ego$alter)) [1] ".altID" ".egoID" "sexo" "edad" "educ" "relig"
[7] "ideol" "barrio" "relacion" "rel" Modelo 1
modelo1 <- ergm.ego(elsoc_ego ~
#edges +
#degree(1:5) +
nodefactor("sexo", levels = -2) +
nodefactor("educ") +
nodefactor("ideol") +
nodefactor("relig") +
nodematch("sexo", diff=TRUE) +
nodematch("educ", diff=TRUE) +
nodematch("ideol", diff=TRUE)+
nodematch("relig", diff=TRUE)+
absdiff("edad"),
# constraints = constraint.formula,
control=control.ergm.ego(ppopsize=5000,
ppop.wt=ppopwt,
stats.wt="data",
stats.est="survey"),
ergm = control.ergm(init.method = "MPLE",
MCMC.burnin = 2e4,
MCMC.interval = 1e4,
MCMC.samplesize = 5000,
parallel = 16,
SAN.nsteps = 1e6,
MCMLE.maxit = 20,
seed = 123),
)Constructing pseudopopulation network.Note: Constructed network has size 4912, different from requested 5000. Estimation should not be meaningfully affected.Unable to match target stats. Using MCMLE estimation.Starting maximum pseudolikelihood estimation (MPLE):Obtaining the responsible dyads.Evaluating the predictor and response matrix.Maximizing the pseudolikelihood.Finished MPLE.Starting Monte Carlo maximum likelihood estimation (MCMLE):Iteration 1 of at most 60:Optimizing with step length 0.6837.The log-likelihood improved by 2.3769.Estimating equations are not within tolerance region.Iteration 2 of at most 60:Optimizing with step length 1.0000.The log-likelihood improved by 1.3225.Estimating equations are not within tolerance region.Iteration 3 of at most 60:Optimizing with step length 1.0000.The log-likelihood improved by 0.1730.Estimating equations are not within tolerance region.Iteration 4 of at most 60:Optimizing with step length 1.0000.The log-likelihood improved by 0.0846.Convergence test p-value: 1.0000. Not converged with 99% confidence; increasing sample size.
Iteration 5 of at most 60:
Optimizing with step length 1.0000.
The log-likelihood improved by 0.3541.
Estimating equations are not within tolerance region.
Iteration 6 of at most 60:
Optimizing with step length 1.0000.
The log-likelihood improved by 0.5360.
Estimating equations are not within tolerance region.
Estimating equations did not move closer to tolerance region more than 1 time(s) in 4 steps; increasing sample size.
Iteration 7 of at most 60:
Optimizing with step length 1.0000.
The log-likelihood improved by 0.1198.
Estimating equations are not within tolerance region.
Iteration 8 of at most 60:
Optimizing with step length 1.0000.
The log-likelihood improved by 0.0667.
Convergence test p-value: 0.9996. Not converged with 99% confidence; increasing sample size.
Iteration 9 of at most 60:
Optimizing with step length 1.0000.
The log-likelihood improved by 0.1090.
Estimating equations are not within tolerance region.
Iteration 10 of at most 60:
Optimizing with step length 1.0000.
The log-likelihood improved by 0.1192.
Estimating equations are not within tolerance region.
Estimating equations did not move closer to tolerance region more than 1 time(s) in 4 steps; increasing sample size.
Iteration 11 of at most 60:
Optimizing with step length 1.0000.
The log-likelihood improved by 0.0471.
Convergence test p-value: 0.4100. Not converged with 99% confidence; increasing sample size.
Iteration 12 of at most 60:
Optimizing with step length 1.0000.
The log-likelihood improved by 0.0346.
Convergence test p-value: 0.0020. Converged with 99% confidence.
Finished MCMLE.
This model was fit using MCMC. To examine model diagnostics and check
for degeneracy, use the mcmc.diagnostics() function.Warning: Argument(s) 'ergm' were not recognized or used. Did you mistype an
argument name?#?control.ergm.ego
#??ignore.max.altersSummary
summary(modelo1)Call:
ergm.ego(formula = elsoc_ego ~ nodefactor("sexo", levels = -2) +
nodefactor("educ") + nodefactor("ideol") + nodefactor("relig") +
nodematch("sexo", diff = TRUE) + nodematch("educ", diff = TRUE) +
nodematch("ideol", diff = TRUE) + nodematch("relig", diff = TRUE) +
absdiff("edad"), control = control.ergm.ego(ppopsize = 5000,
ppop.wt = ppopwt, stats.wt = "data", stats.est = "survey"),
ergm = control.ergm(init.method = "MPLE", MCMC.burnin = 20000,
MCMC.interval = 10000, MCMC.samplesize = 5000, parallel = 16,
SAN.nsteps = 1e+06, MCMLE.maxit = 20, seed = 123))
Monte Carlo Maximum Likelihood Results:
Estimate Std. Error MCMC % z value Pr(>|z|)
offset(netsize.adj) -8.4994365 0.0000000 0 -Inf < 1e-04 ***
nodefactor.sexo.1 -0.2885474 0.2388619 0 -1.208 0.227044
nodefactor.educ.2 0.3049821 0.0784976 0 3.885 0.000102 ***
nodefactor.educ.3 0.2704014 0.0979725 0 2.760 0.005781 **
nodefactor.educ.4 0.0672247 0.0980471 0 0.686 0.492942
nodefactor.ideol.2 -0.0747442 0.1382029 0 -0.541 0.588625
nodefactor.ideol.3 -0.1007495 0.1146232 0 -0.879 0.379421
nodefactor.ideol.4 0.1267838 0.1354388 0 0.936 0.349223
nodefactor.ideol.5 0.0156922 0.1117448 0 0.140 0.888321
nodefactor.ideol.6 0.2787322 0.1086339 0 2.566 0.010294 *
nodefactor.relig.2 -0.4745734 0.1176390 0 -4.034 < 1e-04 ***
nodefactor.relig.3 0.0263535 0.1293003 0 0.204 0.838497
nodefactor.relig.4 0.2673704 0.1065402 0 2.510 0.012088 *
nodematch.sexo.1 0.6639366 0.2428196 0 2.734 0.006252 **
nodematch.sexo.2 0.2079429 0.2412359 0 0.862 0.388693
nodematch.educ.1 0.8357836 0.1301471 0 6.422 < 1e-04 ***
nodematch.educ.2 0.3752702 0.1055680 0 3.555 0.000378 ***
nodematch.educ.3 0.6975375 0.1330534 0 5.243 < 1e-04 ***
nodematch.educ.4 1.6478958 0.1327725 0 12.411 < 1e-04 ***
nodematch.ideol.1 1.7033774 0.2036293 0 8.365 < 1e-04 ***
nodematch.ideol.2 1.0841183 0.3355293 0 3.231 0.001233 **
nodematch.ideol.3 -0.0003412 0.2294421 0 -0.001 0.998813
nodematch.ideol.4 0.3014313 0.2783215 0 1.083 0.278794
nodematch.ideol.5 1.5431064 0.2066599 0 7.467 < 1e-04 ***
nodematch.ideol.6 0.5745488 0.1326972 0 4.330 < 1e-04 ***
nodematch.relig.1 0.8679198 0.1370340 0 6.334 < 1e-04 ***
nodematch.relig.2 2.4035463 0.1652878 0 14.542 < 1e-04 ***
nodematch.relig.3 0.7822271 0.2575841 0 3.037 0.002391 **
nodematch.relig.4 0.7131643 0.1566308 0 4.553 < 1e-04 ***
absdiff.edad -0.0295657 0.0022174 0 -13.334 < 1e-04 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
The following terms are fixed by offset and are not estimated:
offset(netsize.adj) Para interpretar los coeficientes, es útil pensar en términos de la probabilidad de que un par dado de nodos tenga un vínculo, condicionada al estado del nodo entre todos los demás pares. Para el término de homofilia de género (segundo orden) en el modelo anterio: El empate entre dos nodos mujeres, casi cuatriplica las probabilidades (odds) de tener un vínculo en la red observada (por su puesto, manteniendo todo lo demás igual).
Vale indicar también que para todas las variables el coeficiente difiere de cero en al menos un error estándar, lo que sugiere algún efecto no trivial de estas variables en la formación de vínculos en la red.
Bondad de ajuste
La práctica actual para evaluar la bondad de ajuste en modelos ERGM es simular primero numerosos gráficos aleatorios del modelo ajustado y luego comparar varios resúmenes de estos gráficos con los del gráfico observado originalmente. Si las características de los grafos de red observados no coinciden con los valores típicos que surgen de las realizaciones del modelo de gráfico aleatorio ajustado, esto sugiere diferencias sistemáticas entre la clase especificada de modelos y los datos y, por lo tanto, una falta de bondad.
En general, al evaluar la bondad de ajuste en el modelado de redes, los resúmenes de uso común incluyen la distribución de cualquier número de los diversos resúmenes de la estructura de la red: como el grado, la centralidad y la distancia geodésica. Con los ERGMs, sin embargo, una elección natural de resumen son las propias estadísticas \(g\) que definen el ERGM (es decir, las llamadas estadísticas suficientes). Para evaluar la bondad de ajuste de nuestro modelo anterior de homofilia, la función ergm ejecuta las simulaciones de Monte Carlo necesarias y calcula las comparaciones con la red original en términos de las distribuciones de cada uno de los estadísticos en el modelo.
plot(gof(modelo1))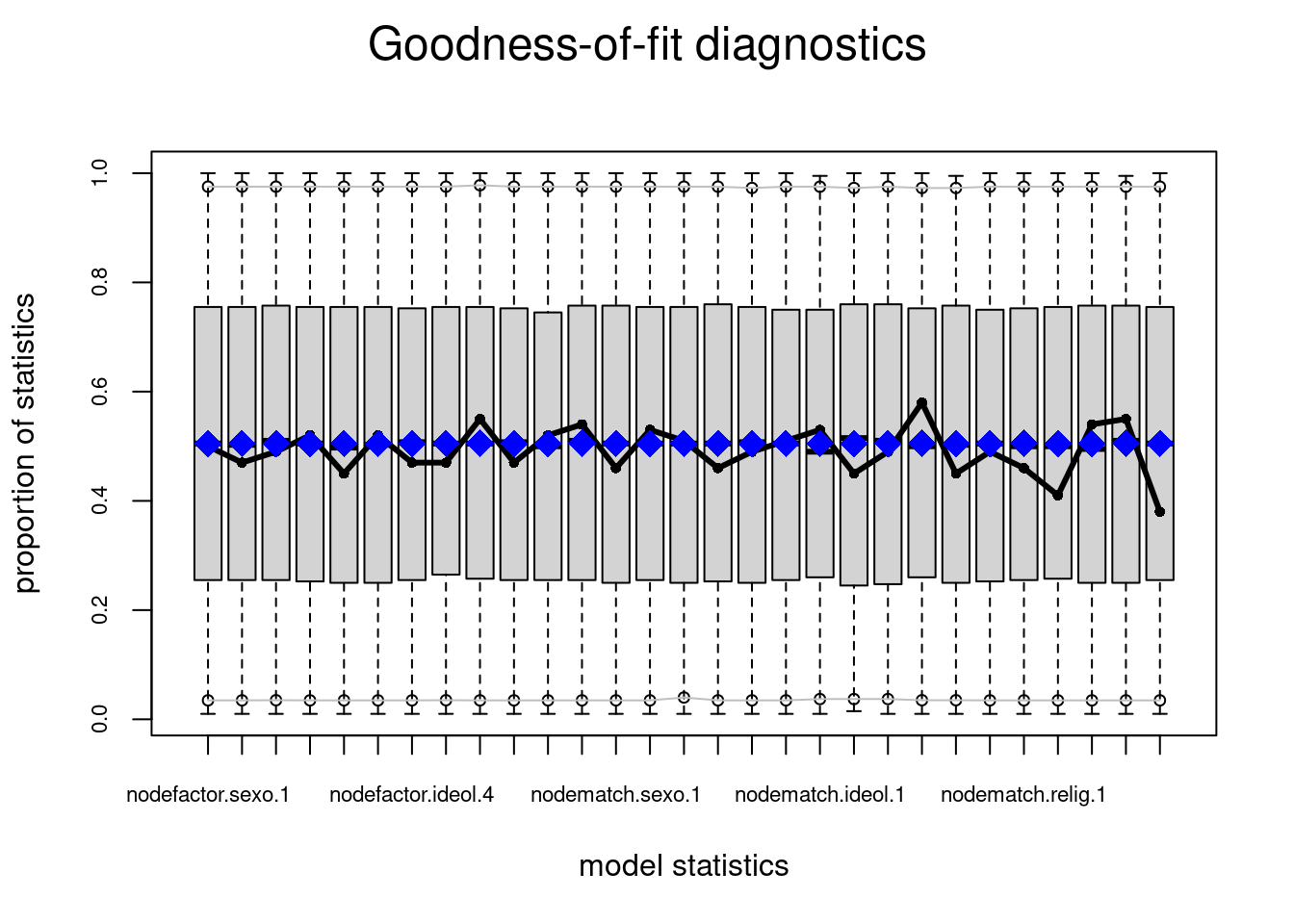
Considerando las características particulares capturadas por las estadísticas, el ajuste del modelo es bastante bueno en general, toda vez que las estadísticas observadas están bastante cerca de la mediana de los valores simulados en la mayoría de los casos.
plot(gof(modelo1, GOF="degree"))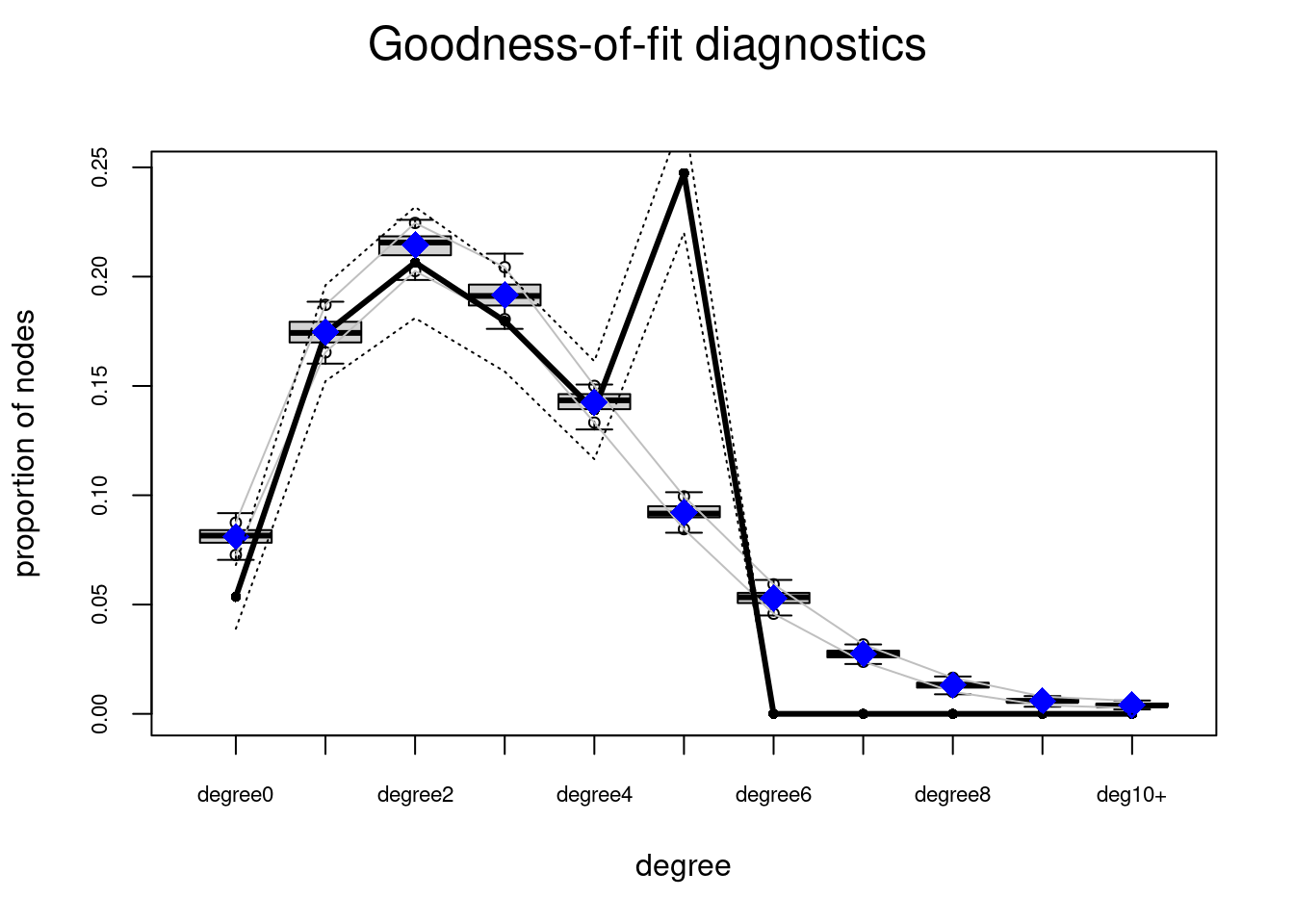
MCMC
mcmc.diagnostics(modelo1, which = "plots")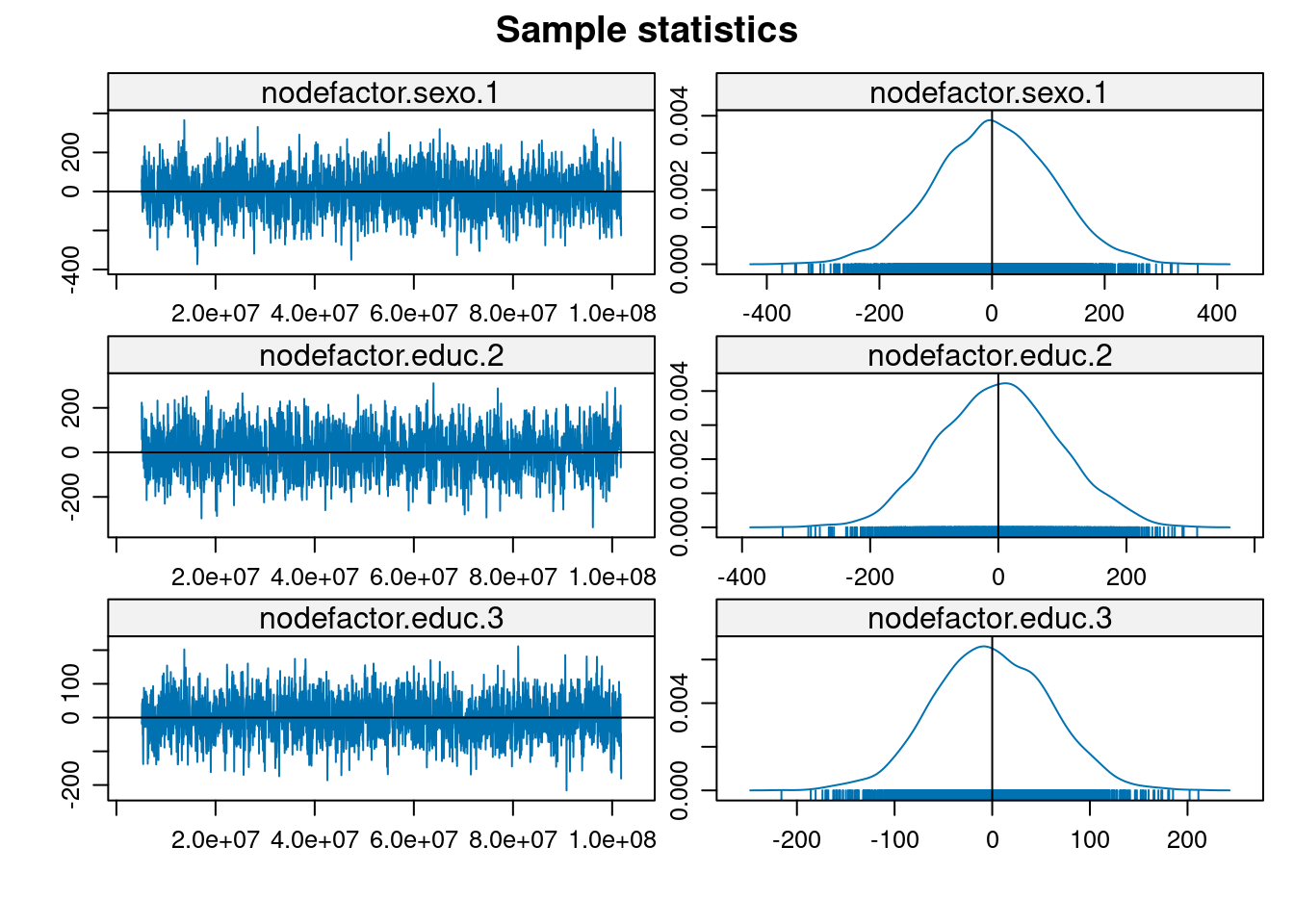
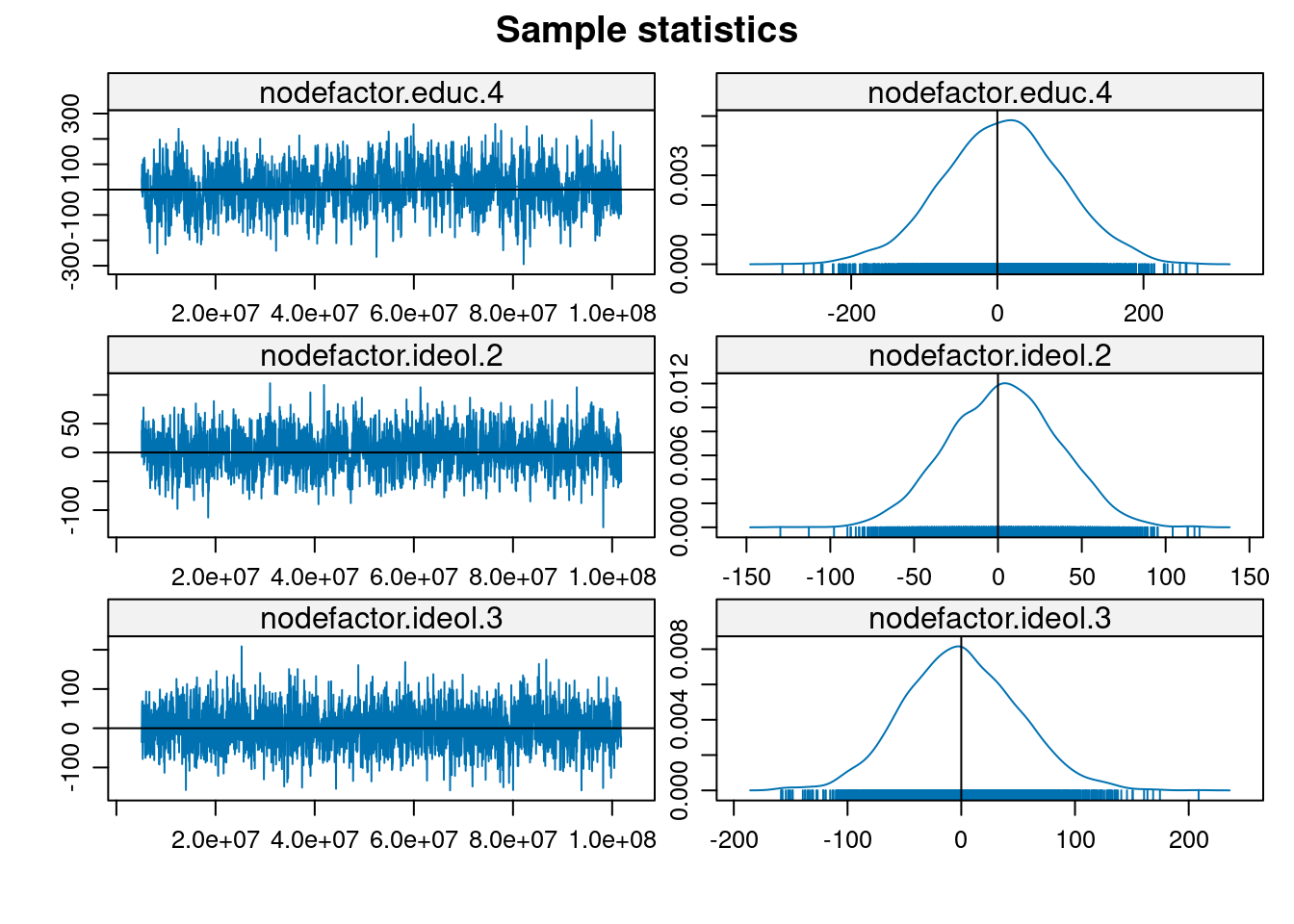
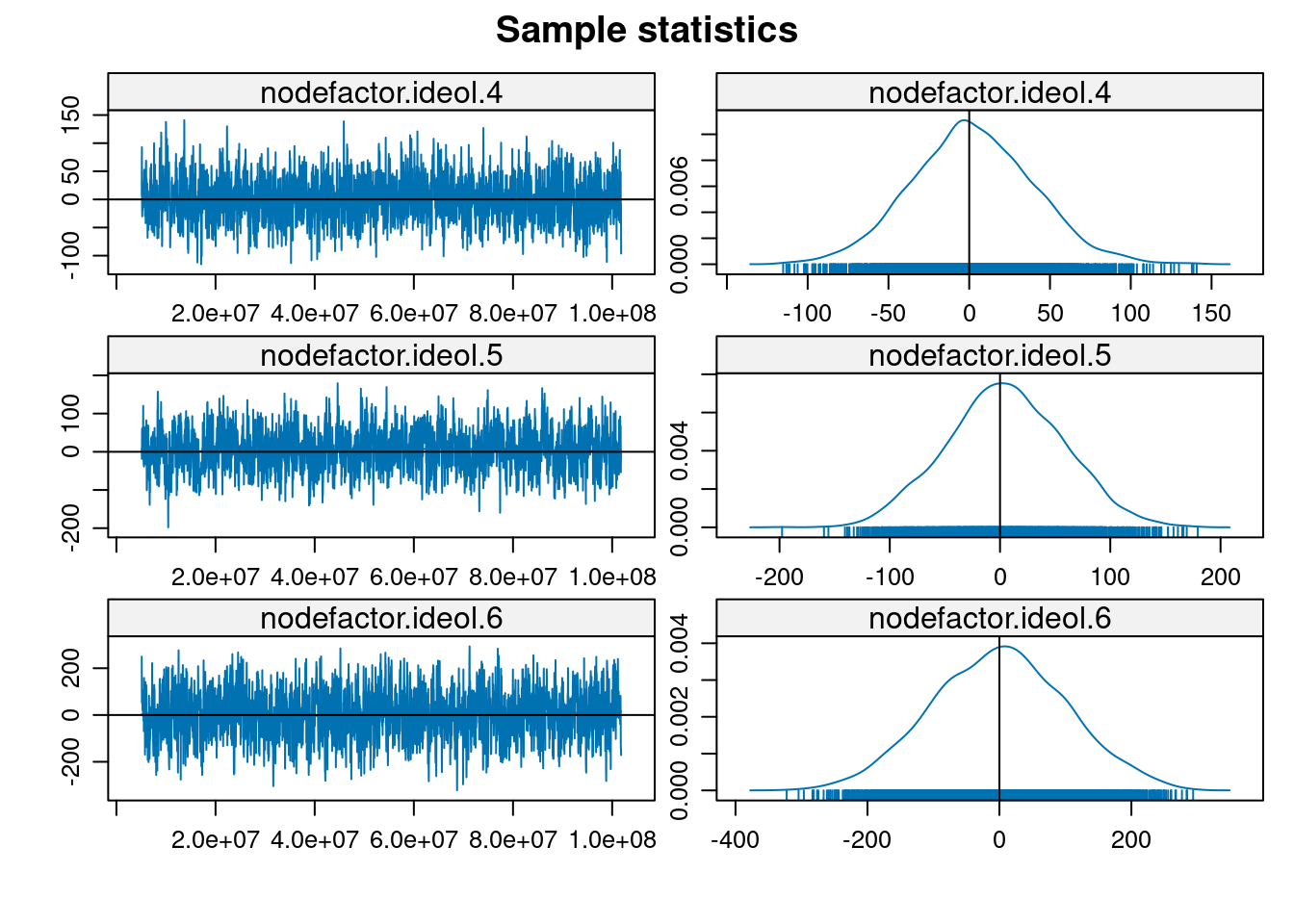
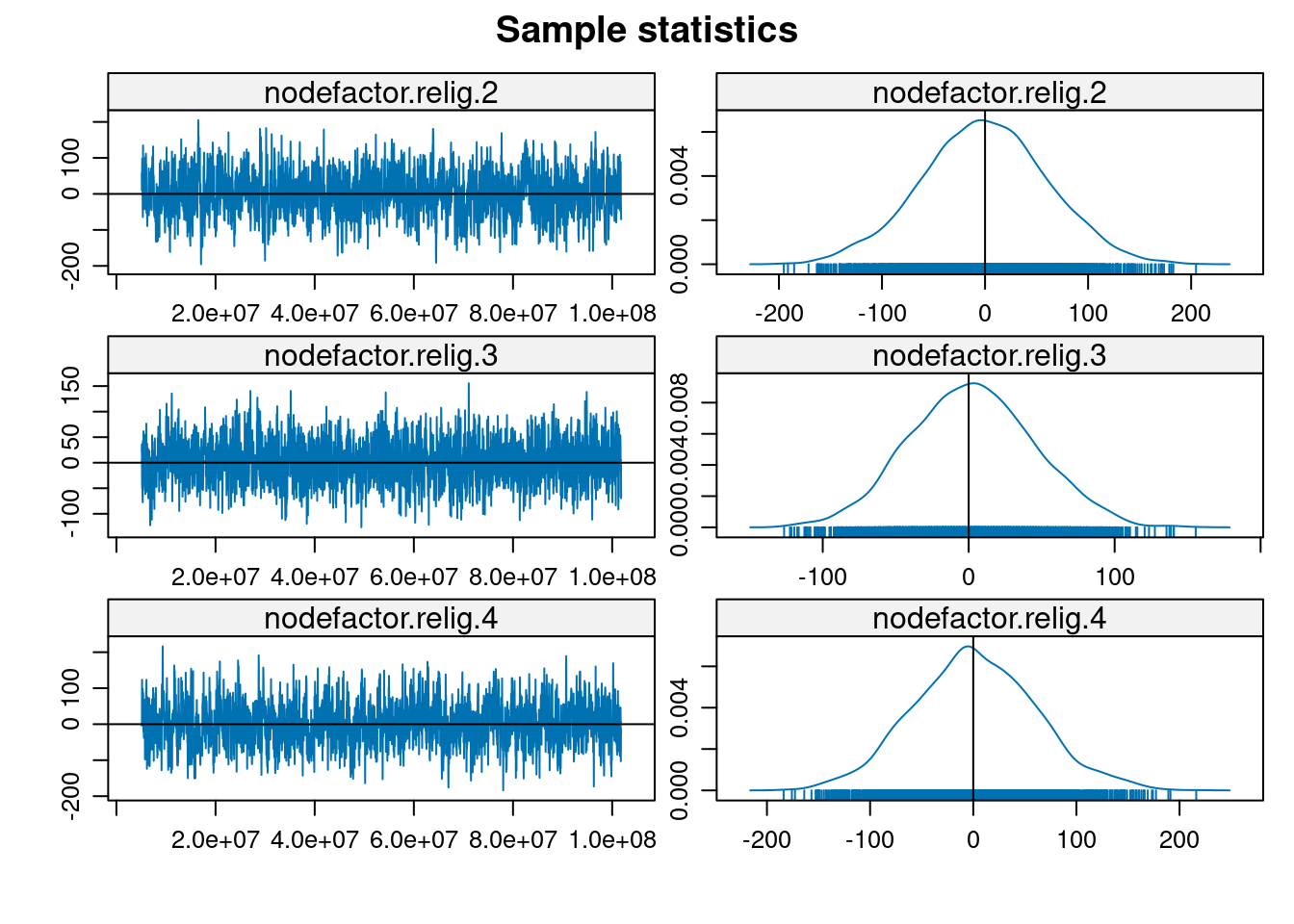
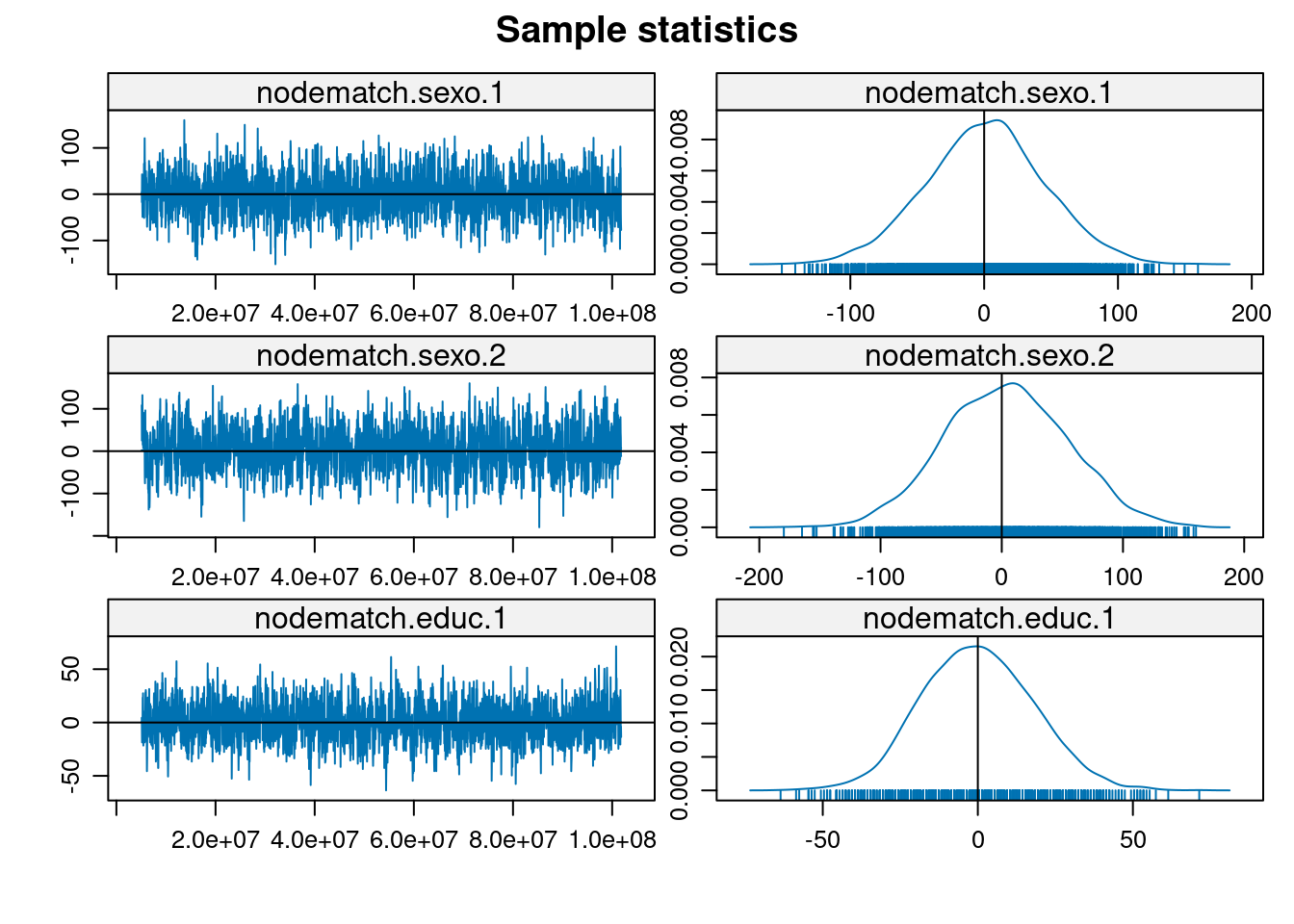
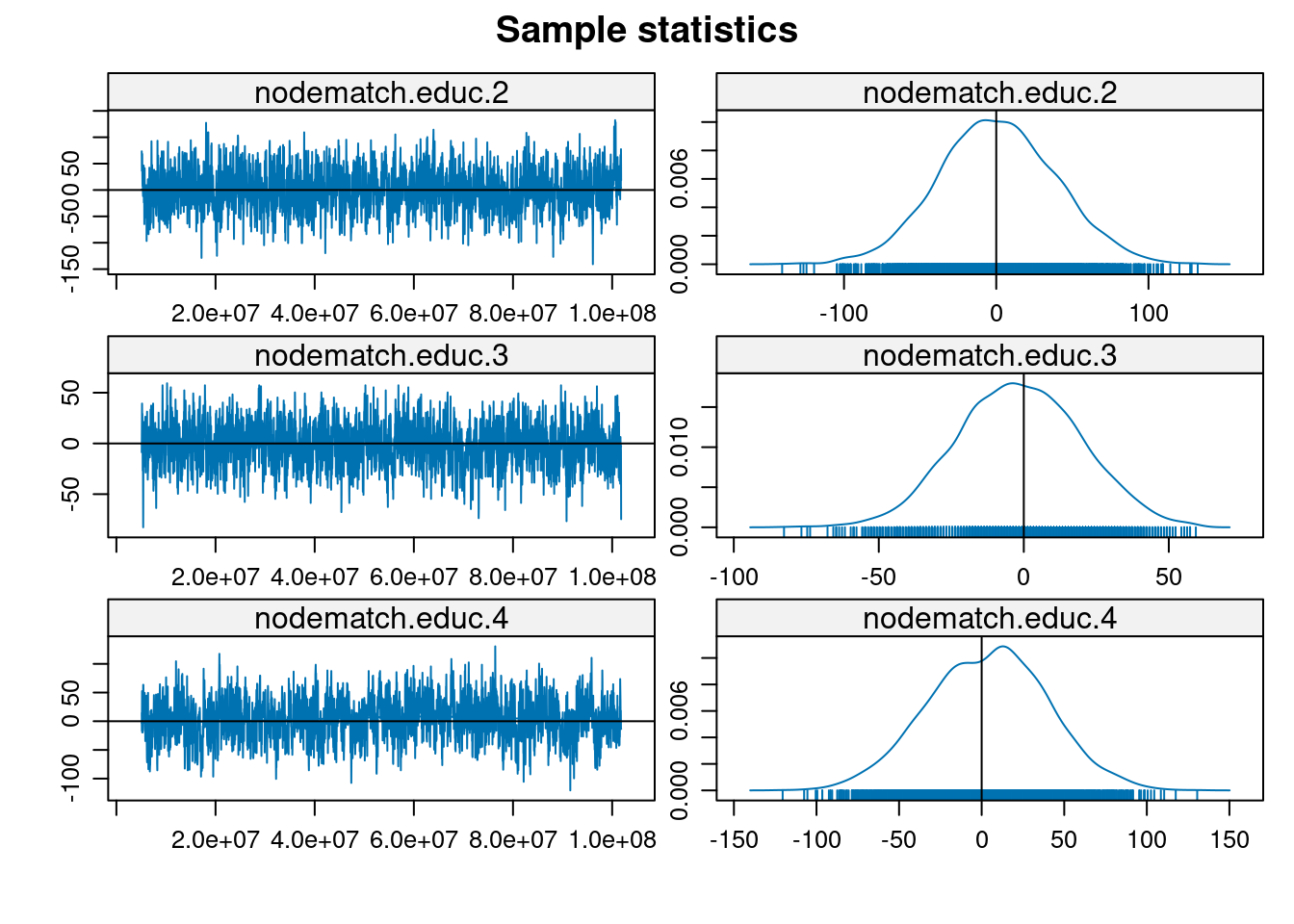
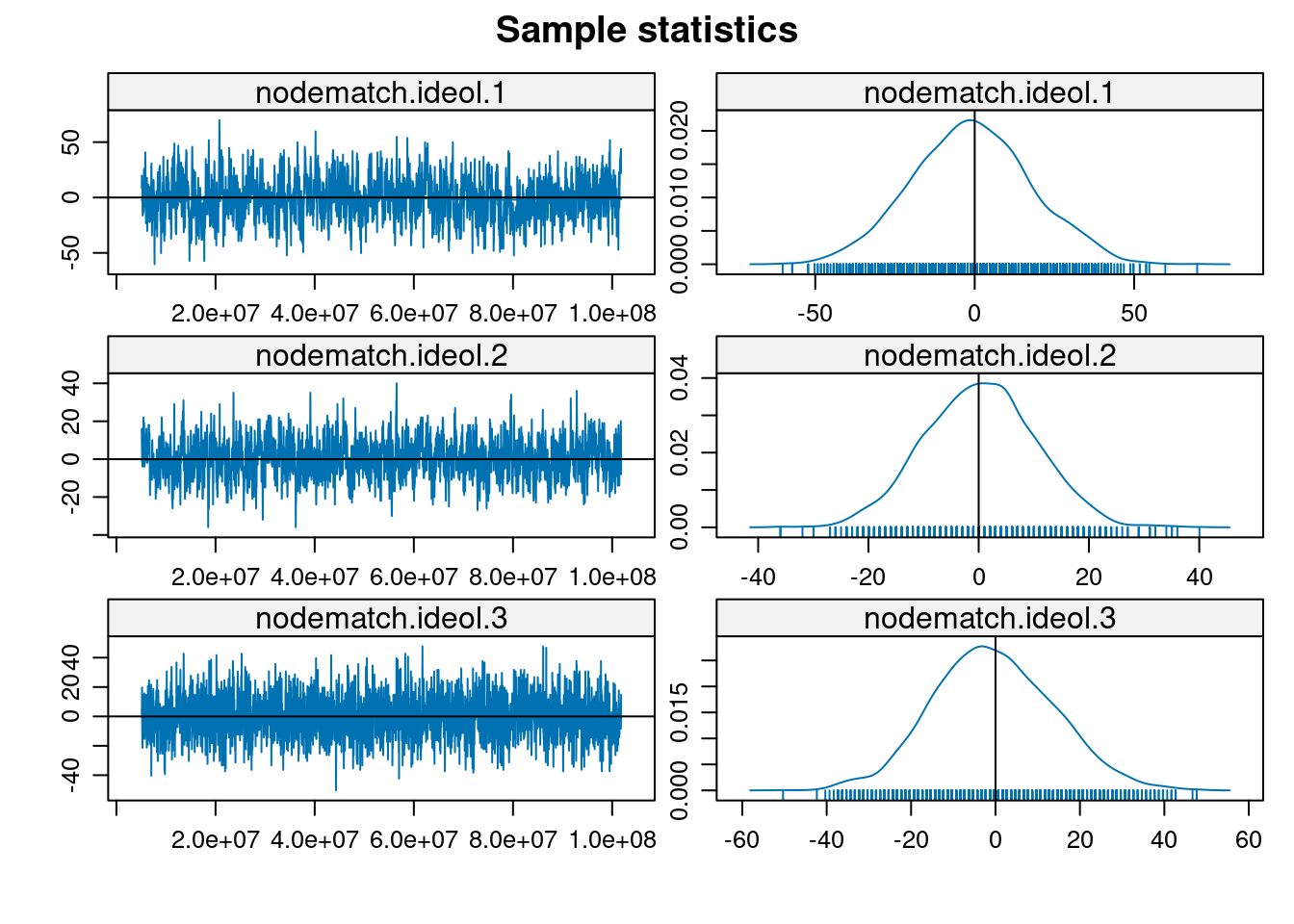
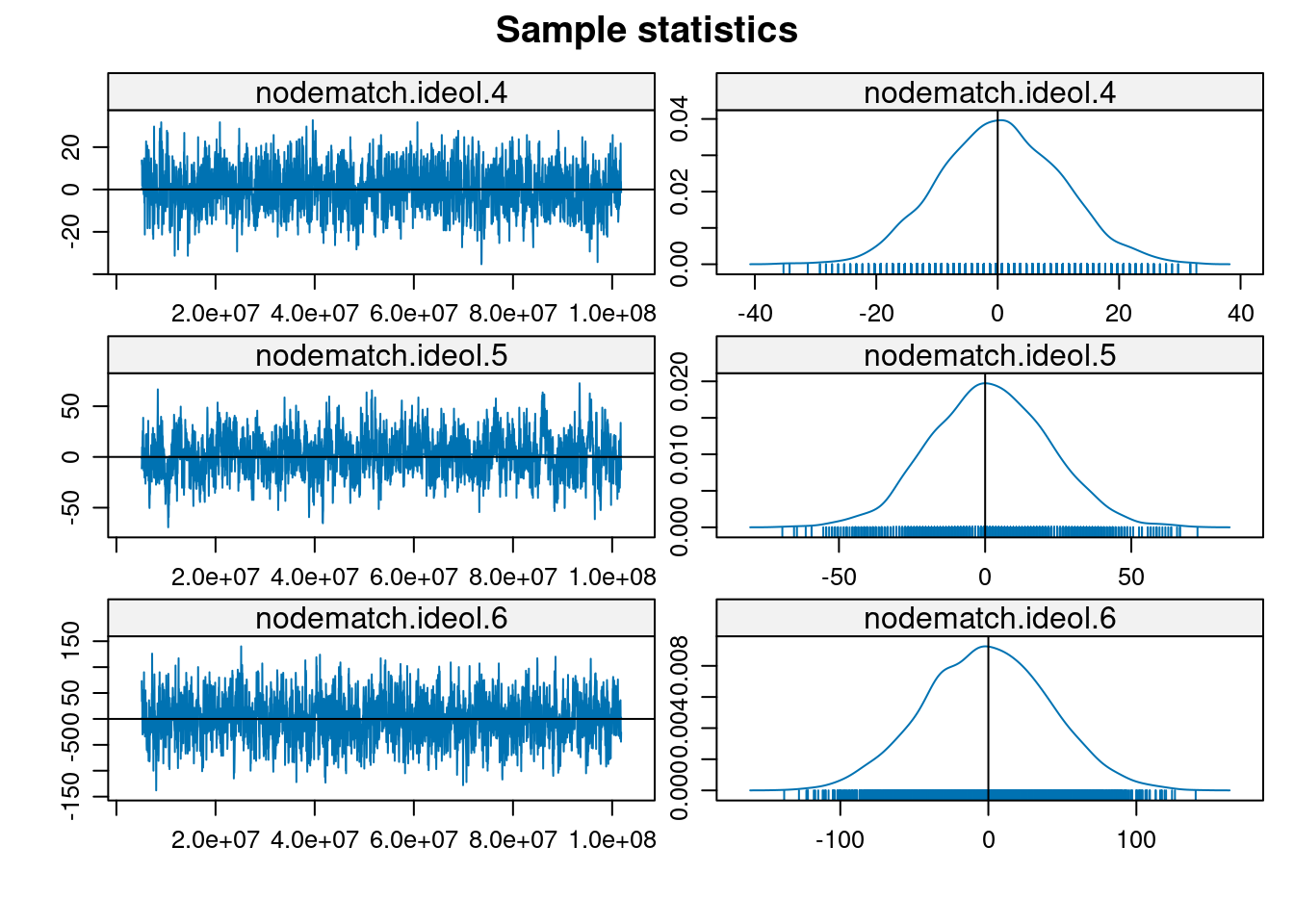
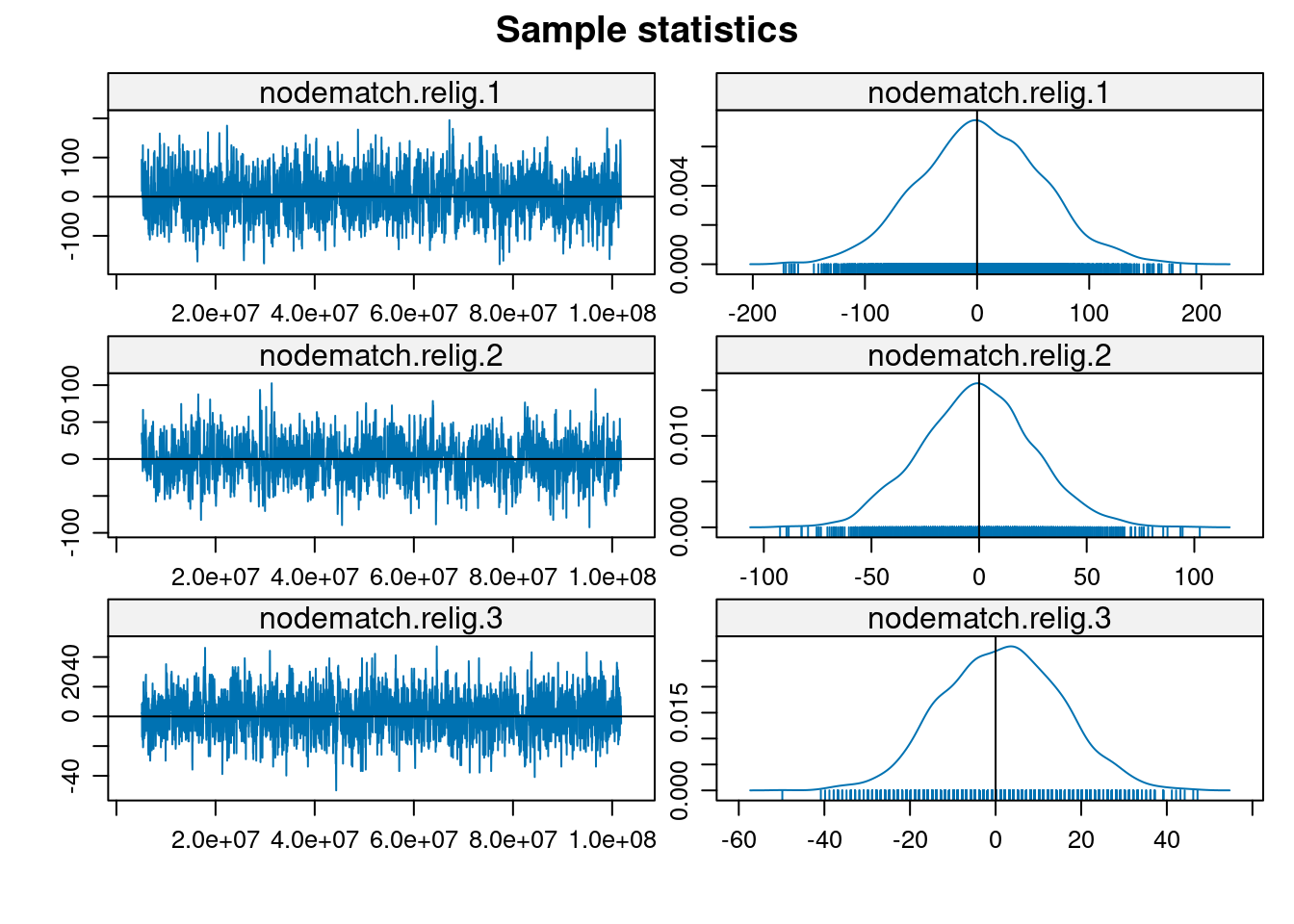
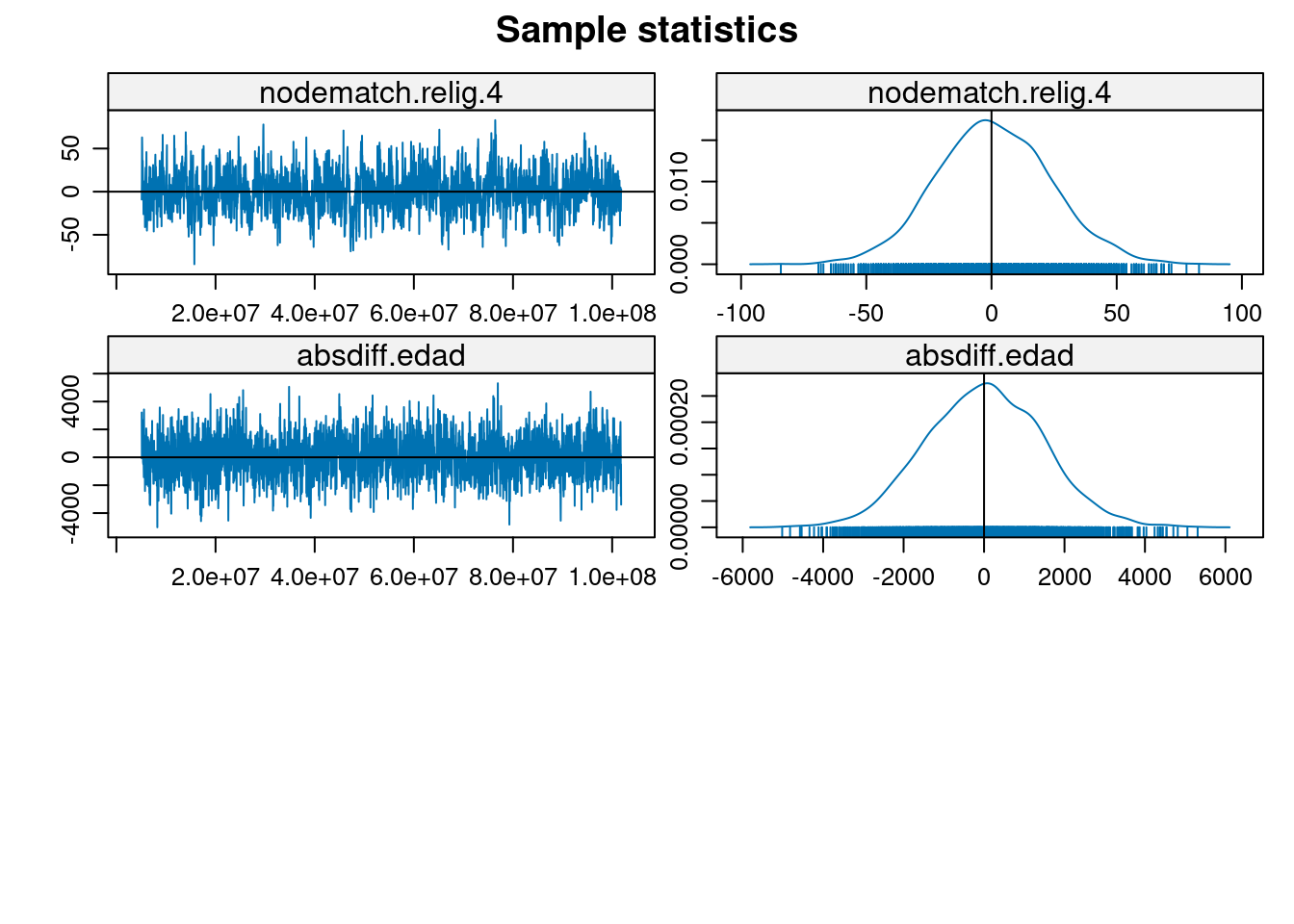
Note: To save space, only one in every 2 iterations of the MCMC sample
used for estimation was stored for diagnostics. Sample size per chain
was originally around 5904 with thinning interval 16384.
Note: MCMC diagnostics shown here are from the last round of
simulation, prior to computation of final parameter estimates.
Because the final estimates are refinements of those used for this
simulation run, these diagnostics may understate model performance.
To directly assess the performance of the final model on in-model
statistics, please use the GOF command: gof(ergmFitObject,
GOF=~model).simulate
sim.modelo1 <- simulate(modelo1, popsize=500,
control=control.simulate.ergm.ego(
simulate=control.simulate.formula(MCMC.burnin=2e6)))Note: Constructed network has size 244 different from requested 500. Simulated statistics may need to be rescaled.plot(sim.modelo1, vertex.col="educ")
legend('bottomleft',fill=1:4,legend=paste('Eduación',1:4),cex=0.75)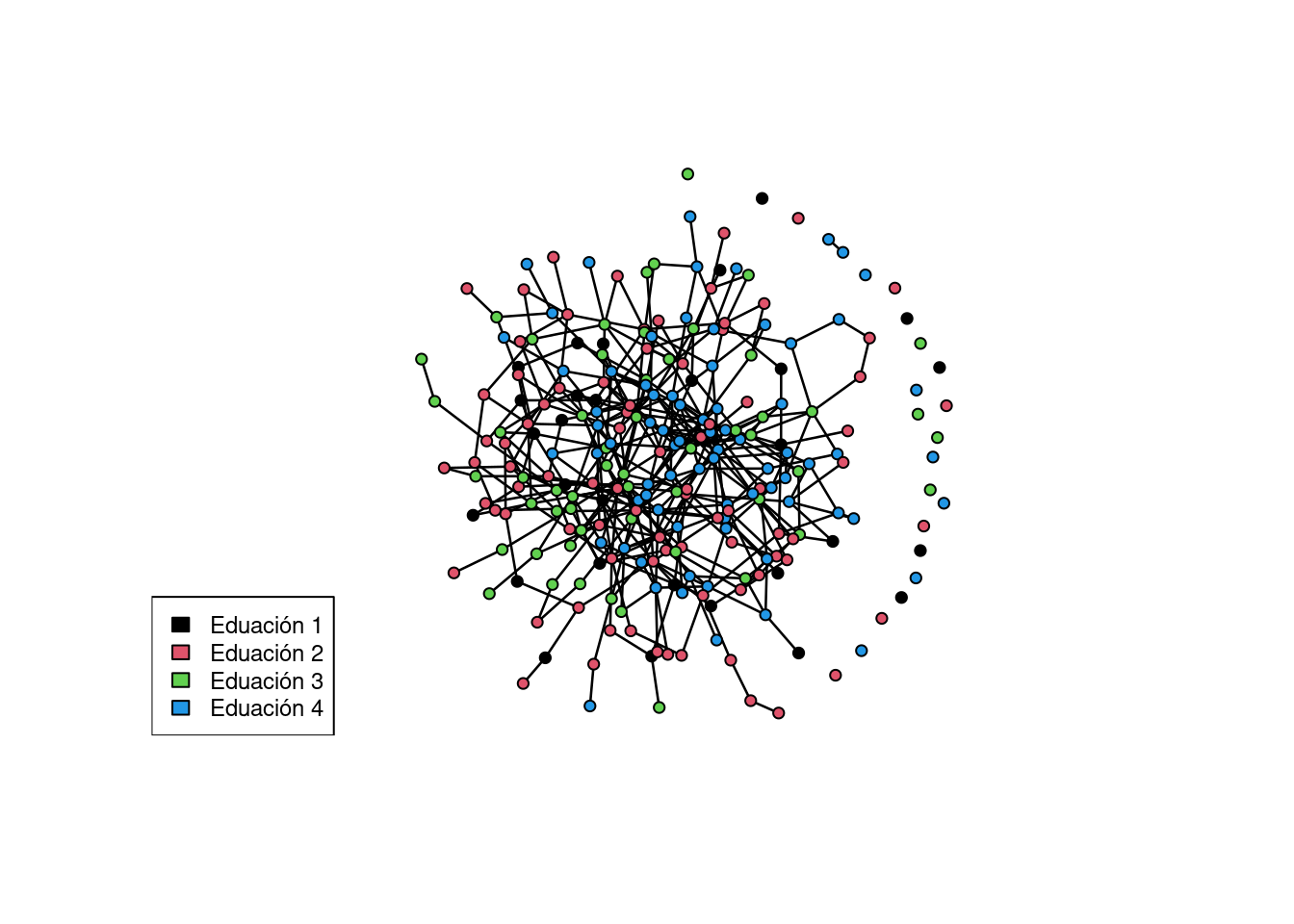
Tidy
broom::tidy(modelo1, exponentiate = TRUE, conf.int = TRUE, conf.level = 0.99)Warning in tidy.ergm(modelo1, exponentiate = TRUE, conf.int = TRUE, conf.level
= 0.99): Exponentiating but model didn't use log or logit link.# A tibble: 30 × 8
term estimate std.error mcmc.error statistic p.value conf.low conf.high
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 offset(ne… 0.000204 0 0 -Inf 0 0.000204 0.000204
2 nodefacto… 0.749 0.239 0 -1.21 2.27e-1 0.405 1.39
3 nodefacto… 1.36 0.0785 0 3.89 1.02e-4 1.11 1.66
4 nodefacto… 1.31 0.0980 0 2.76 5.78e-3 1.02 1.69
5 nodefacto… 1.07 0.0980 0 0.686 4.93e-1 0.831 1.38
6 nodefacto… 0.928 0.138 0 -0.541 5.89e-1 0.650 1.32
7 nodefacto… 0.904 0.115 0 -0.879 3.79e-1 0.673 1.21
8 nodefacto… 1.14 0.135 0 0.936 3.49e-1 0.801 1.61
9 nodefacto… 1.02 0.112 0 0.140 8.88e-1 0.762 1.35
10 nodefacto… 1.32 0.109 0 2.57 1.03e-2 0.999 1.75
# ℹ 20 more rowsPredict
#predict(modelo1, type = "response")